- From: Dave Raggett <dsr@w3.org>
- Date: Fri, 24 May 2024 09:44:28 +0100
- To: public-cogai <public-cogai@w3.org>
- Message-Id: <B8009825-6226-4C1D-AD36-C6097565434C@w3.org>
Children master language with surprisingly little data. Noam Chomsky referred to this as the poverty of the stimulus (Language and learning: 1980) and used it to justify claims for an innate language acquisition capability (a genetically determined universal grammar). Some twenty years later in 2002 Henry Brighton presented a theory on how compositional syntax emerges from cultural transmission, showing how language patterns that support generalisation are more likely to survive unscathed as they are passed around the population of language users. Children memorise language patterns in the context of the most likely intended meaning for each utterance. Observing a given pattern implies a previously associated meaning if the pattern has been seen before. Otherwise, the meaning can be derived a process of generalisation or invention (plausible guesses). The associated meaning for memorised patterns is updated as further evidence is obtained. How can we design neural networks that can memorise utterances and generalise them? How can these networks make plausible guesses as to the intended meaning, and use this to support generalisation? Conventional deep learning assumes a loss function that characterises the difference between the predicted output and the target output. This is used to drive gradient descent through the model’s parameter space via back propagation through time. The model parameters are then updated by multiplying the gradient by the learning rate, which is typically a small positive number between 0.01 and 0.0001. This is a slow process and unsuited to one-shot incremental learning. That is however key to survival for animals in a hostile environment, as animals that learn quickly are more likely to survive and reproduce. We thus need an alternative framework for learning. The brain is very unlikely to use back propagation, but is nevertheless pretty effective at incremental learning. This provides grounds for optimism in respect to finding effective algorithms for artificial neural networks. Work on pulsed neural networks is showing the potential for alternatives to back propagation. These involve local learning under direction of learning signals. In the brain, the latter includes chemical signals, i.e. neurotransmitters such as dopamines that target classes of neurons, as well as lateral connections from other regions of the neocortex. A 2020 study by Scherr, Stöckl, and Maass looks at using a recurrent pulsed neural network to generate the learning signals for the learning network. The learning signal generator is trained using back propagation over a collection of similar tasks. The model parameters for local learning are then computed in terms of a weighted sum over the learning signals, and so-called eligibility traces for each connected pair of neurons in the learning network. These traces correspond to Hebbian learning based upon temporal correlations between a neuron's input and output:  In essence, this uses a slow process for learning to learn, and a fast process for recording individual memory traces. I am hoping to implement these ideas and see how far they can be taken. For this, I plan to use conventional artificial neurons with continuous signals rather than pulsed neurons, as this will allow me to take advantage of PyTorch’s support for GPUs for hardware acceleration. In the long run, I expect pulsed neural networks to dominate as they use a tiny fraction of the electrical power needed by GPU based models. Neuromorphic hardware is still in its infancy, and may take decades to mature, but has a bright future both in the cloud and the edge. You can see further details at: https://github.com/w3c/cogai/blob/master/agents/incremental-learning.md Best regards, Dave Raggett <dsr@w3.org>
Attachments
- text/html attachment: stored
- image/png attachment: Screenshot_2024-05-24_at_09.14.52.png
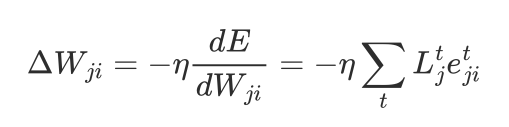
Received on Friday, 24 May 2024 08:44:41 UTC