- From: Dave Raggett <dsr@w3.org>
- Date: Mon, 3 Aug 2020 15:54:37 +0100
- To: public-cogai@w3.org
- Message-Id: <692845DF-D917-4147-A9D4-65D3BBD66EFA@w3.org>
I thought you might be interested in hearing how I am getting on with the natural language demos for Cognitive AI, and very much welcome your comments and insights.
I first worked on very simple natural language utterances to move discs between the towers in the Towers of Hanoi game, see:
https://www.w3.org/Data/demos/chunks/nlp/toh/ <https://www.w3.org/Data/demos/chunks/nlp/toh/>
You can either type the command directly or click the microphone to say the command and in both cases then press the Enter key. Speech recognition uses the cloud based service via the HTML speech API. I understand that Google’s implementation uses neural networks, and works quite well, but not perfectly.
The facts graph provides details for the discs sizes and colours, the lexicon of words and the current state of the game. The rules graph maps the chunks parse tree to a chunk describing the command and then moves the disk with the “move” operation defined by the application.
The parser maps utterances to a sequence of lower case words. These are then scanned one word at a time to construct the parse tree via a shift-reduce parser. The chunks for the parse tree are added to the facts graph, and a goal is injected that looks like the following:
interpret {utterance ?id}
Where the id references the root chunk for the parse tree. This goal triggers the rules that map the utterance to the semantic description of the move command, which activates a simple animation using the HTML canvas.
The aim is for subsequent demos to keep the word by word processing, but to make it concurrent with cognitive processing rather than deferring it to after parsing is finished. Conventional parsers rely on lexical statistics to rank different parse trees, given that natural language is highly ambiguous. Given that the purpose of natural language is communication, I believe it makes more sense to instead focus on cognitive processing to disambiguate choices during parsing and to avoid the need for backtracking. This means that we need a means to concurrently process syntax and semantics.
As a small step towards this, I’ve created a demo involving two communicating cognitive agents, see:
https://www.w3.org/Data/demos/chunks/nlp/dinner/ <https://www.w3.org/Data/demos/chunks/nlp/dinner/>
Click “run demo” to see it in action. The web page creates two cognitive agents with their own facts and rules. Communication is by passing chunks from one agent to the other as goals that trigger rules. I’ve divided the rules into sets that each handle a particular task. See that attached files with the .chk extension. Here is an extract for the customer:
> start {} => greetings {@enter task1}
>
> greetings {@task task1} =>
> greetings {@do say; message "good evening"}
>
> acknowledge {@task task1} =>
> find-table {@leave task1; @enter task2}
>
> find-table {@task task2} =>
> table {seats 1; location anywhere; @do say; message "a table for one please"}
>
> table {@task task2; seats 1; location room} =>
> table {seats 1; location window; @do say; message "do you have a seat by the window"}
>
> sorry {@task task2; about table} =>
> okay {@do say; message "that's okay, this table will be fine"},
> state {@leave task2; @enter task3}
In essence, this just uses event-driven state machines where the rule engine keeps track of the currently active tasks for each module. I’ve haven’t bothered with natural language processing here, and instead combine passing a chunk with invoking speech synthesis via the HTML speech API. The concept of entering and leaving tasks is in part inspired by David Harel’s state charts. The tasks in the rule conditions are matched against the set of currently active tasks rather than the properties in the module’s chunk buffer.
Work in computational linguistics and work using deep learning (e.g. GPT-3) are limited to lexical statistics, and unable to generalise and reason at a more abstract level. By compiling statistics over huge corpora equivalent to many millions of books, this has the appearance of progress, but won't help with building general purpose AI. When asked which is heavier, a toaster or a pencil GPT-3 gives the wrong answer, betraying its lack of real understanding. See:
https://www.theverge.com/21346343/gpt-3-explainer-openai-examples-errors-agi-potential <https://www.theverge.com/21346343/gpt-3-explainer-openai-examples-errors-agi-potential>
https://www.technologyreview.com/2020/07/31/1005876/natural-language-processing-evaluation-ai-opinion/ <https://www.technologyreview.com/2020/07/31/1005876/natural-language-processing-evaluation-ai-opinion/>
Reasoning directly with words would be one approach, but given the many different ways of expressing the same things, and the ambiguity of human languages, that would involve a vast number of rules and be difficult to train successfully.
At the other extreme, we could attempt to translate words into logical representations as a basis for inferencing. This raises the challenge of what that representation should be, and whether it is flexible enough to cover the semantics of natural language. Common Logic, for instance, isn't flexible enough in general. For more details, see:
https://www.w3.org/2004/12/rules-ws/slides/pathayes.pdf <https://www.w3.org/2004/12/rules-ws/slides/pathayes.pdf>
Philip Johnson-Laird notes that humans don't reason with logic or bayesian statistics, but rather with mental models that denote a particular possibility. Mental models are iconic in the way each part of the model maps to what it represents. Unfortunately, he doesn't give a clear idea of how such models are constructed in practice given the cognitive machinery available. For more details, see:
https://www.pnas.org/content/pnas/107/43/18243.full.pdf <https://www.pnas.org/content/pnas/107/43/18243.full.pdf>
https://www.academia.edu/974345/Mental_models_an_interdisciplinary_synthesis_of_theory_and_methods <https://www.academia.edu/974345/Mental_models_an_interdisciplinary_synthesis_of_theory_and_methods>
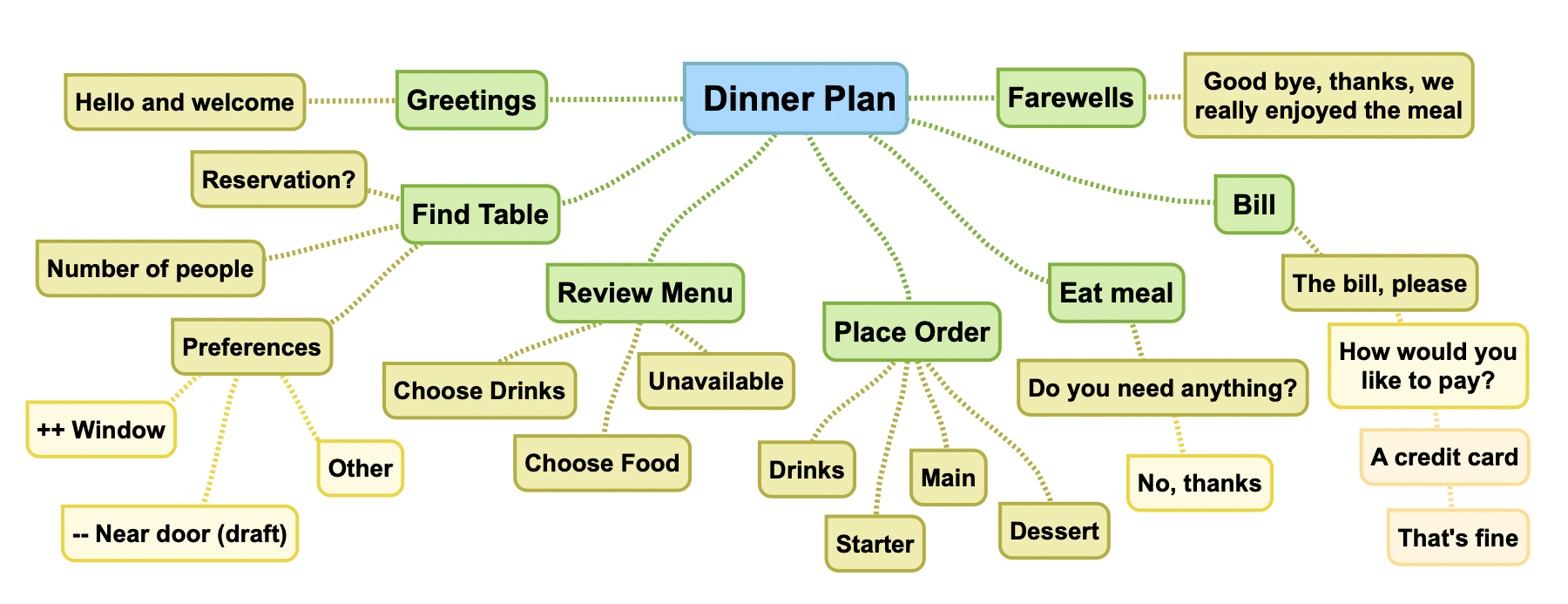
I am now trying to see how model based reasoning could be applied to the restaurant scenario. I’ve created a mind map as an initial step:
The next step is to evolve the mind map into a knowledge graph as a mental model that reflects previous visits to restaurants. The primary nodes (in green) could be formed into a temporal sequence describing the order that they have to be carried out. The secondary nodes could be associated with flow charts modelled as facts describing typical behaviours that are interpreted by a generic rule-set.
Utterances can then be interpreted by how they relate to the knowledge graph. This could involve spreading activation from the lexical entries for words to the concepts in the knowledge graph, given that the current context is having dinner in a restaurant. Given the utterance “a table for one please” this would activate “find table” and “number of people”.
“Please” implies a speech intent, in this case a question. My analysis of typical dinner dialogues suggests an extensive set of intents:
• hello - when greeting someone
• hello-back - as a response to someone greeting you
• farewell - when saying goodbye
• farewell-back - as a response to someone saying goodbye
• information - e.g. a table for one
• info-question - e.g. what would you like for the main course
• yes-no-question - in combination with information
• yes - positive response to yes-no question
• no - negative response to yes-no question
• nack - acknowledgement when given a negative response
• thanks - acknowledgement to a positive response
• echo - echoing back information as confirmation it has been heard
• ack - when a request for information has been satisfied
• pointer - e.g. pointing when saying "just here"
• acceptance - indicating that something is acceptable
• opinion - e.g. the steak pie is very good
Inferring the intent from the utterance is likewise doable in terms of spreading activation from the words in the utterance. “Sorry", "I am afraid not", and "I am sorry" all mean no. These words can all have an associative link to the speech intent for no. This involves semantic associations for lexical entries. e.g. for an intent and a concept.
Another challenge is to distinguish unconscious from conscious processing of language. Our ability to process language quickly suggests that a lot of the processing must be unconscious, i.e. using cortical graph algorithms rather than explicit rules executed by the cortico-basal ganglia circuit.
One example is our ability as native speakers of a language to effortlessly determine ungrammatical constructs, e.g. “all the tables” is okay, whilst “some the tables” is not, and requires “of” between “some” and “the”, despite the fact that both “all” and “some” are determiners acting as quantifiers. That points to the brains ability to keep track of lexical statistics involving words and word classes. This is relevant to both NLU and NLG.
I still have a long way to go, but at least the road signs are becoming a little easier to read!
Hoping you are enjoying the summer break!
Dave Raggett <dsr@w3.org> http://www.w3.org/People/Raggett
W3C Data Activity Lead & W3C champion for the Web of things
Attachments
- text/html attachment: stored
- image/png attachment: dinner-plan.png
- text/html attachment: stored
- application/octet-stream attachment: crules.chk
- text/html attachment: stored
- application/octet-stream attachment: wrules.chk
- text/html attachment: stored
Received on Monday, 3 August 2020 14:54:47 UTC