- From: Roberto Peon <grmocg@gmail.com>
- Date: Thu, 15 Aug 2013 14:35:31 -0700
- To: Martin Thomson <martin.thomson@gmail.com>
- Cc: HTTP Working Group <ietf-http-wg@w3.org>
- Message-ID: <CAP+FsNcKQ2RCtk7prukECx8aMqpWn941dm61QG+xb3AOn=bdHQ@mail.gmail.com>
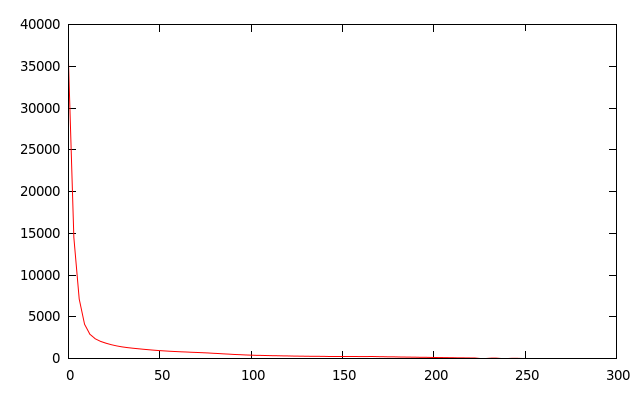
inline On Thu, Aug 15, 2013 at 2:21 PM, Martin Thomson <martin.thomson@gmail.com>wrote: > That's an interesting graph. Let me just clarify two things: > > 1. Does this show the frequency distribution for the distance from the > current appearance of a given name/value pair to the most recent appearance > of the same pair. Aren't we more interested in the distance to the first > appearance of the same pair? Would it make sense to also have data on > distance between last appearance and first appearance as well (maybe we do > want the triangular distribution resulting from multiple consecutive > :method=GET pairings, and number of reuses is interesting, but duration of > usage is also interesting)? > > Correct. This is the freq distribution for the most recent occurance of the key/value pair that the compressor has just encountered. i.e., the compressor is fed compressHeader(key, value), and this is the distance to the most recent matching key, value The distance to the first appearance is algorithmically the wrong thing to do-- Why scan N, where N > k key-values when you can just scan k? Also, if one wishes to create a 'constant effort' encoder, which is interesting for security and real-time performance, then you want to be scanning at most L items, and you'll want those L items to have the highest probability of including the item you're hoping to compress. I'd never stop someone from looking at it in the ways you suggest, though-- one could build a 'from the oldest-entry' freq table, which, who knows, could possibly look the same (but I sincerely doubt it, given I accidentally did this once :) ). Another way of cutting the cookie would be to scan all entries, and increment that bucket if it happens to be there. This would mean that more than one bucket could be incremented per compressed key-value, but would immuminate the places in-between... > 2. When you say "distance", is this number of messages since last seeing > the same values, or is it the number of headers processed since seeing the > same value? > Number of key-value-pairs since that value had been seen, assuming delta-encoding. -=R > > > On 15 August 2013 14:06, Roberto Peon <grmocg@gmail.com> wrote: > >> I did this testing a while back (look for email entitled "Compression >> analysis of perfect atom-based compressor"). >> >> Someone can hack something up to do this again on the new corpus, but the >> data was pretty unequivocal. >> I've attached a PNG version of the freq vs dist-from-newest-element graph. >> >> Again, this was with a "perfect" FIFO-based compressor, which had no >> expiry and infinite space over the test corpus (with each domain having a >> separate compressor, but summing into the final total) that was available >> to us before the new larger, if munged, corpus that was recently >> contributed. >> >> >> This is a graph of the number of times that you'd like to have >> backreferenced something (y-axis) at the distance from the newest element >> (x-axis). >> If we always found that we wished to backreference the 10th most recent >> item (which is most certainly not the case, but IF), then this graph would >> be a single spike at 10. >> >> And here is the data. >> [image: Inline image 1] >> I'd welcome someone computing this again! >> >> -=R >> >> >> On Thu, Aug 15, 2013 at 1:30 PM, Martin Thomson <martin.thomson@gmail.com >> > wrote: >> >>> On 15 August 2013 13:00, Roberto Peon <grmocg@gmail.com> wrote: >>> > Currently, index 0 is the 'top' of the table, and when a new header is >>> added >>> > using incremental indexing, it is added at the 'bottom' (i.e. the >>> highest >>> > number index). >>> >>> There are two separate issues here. Strangely, the right decision >>> depends on the same question. See below. >>> >>> The first is whether the most recently added values should appear at >>> index 0 or index n when adding to the table. This wouldn't matter at >>> all if it weren't for the fact that small values take less space to >>> encode. So, any decision we make should be based on what we believe >>> is going to be reused more often: things that are added recently, or >>> things that have been present for a long time. If it's recent items >>> that are being used more often, we probably need to add at index 0. >>> >>> The second relates to eviction: which items be evicted from the header >>> table? Those that were most recently added, or those that have been >>> around for a long time? As I hinted before, this depends on the same >>> question. >>> >>> Intuitively at least, I believe that there will be a split on the >>> header reuse question. Some things, like :method=GET, are probably >>> going to be quite stable. Other things, like cookies, tend to change >>> such that old values are invalid (Cookie in particular might be a good >>> candidate for substitution). If there is a split, then I can imagine >>> that some optimizations could give good returns... maybe something >>> analogous to a generational garbage collector. But then, I can't >>> imagine a way to avoid the resulting performance and complexity >>> issues. >>> >>> But that's just analysis. Testing might be an easier way to decide, >>> or at least to inform the choice. >>> >> >> >
Attachments
- image/png attachment: freq_vs_dist_from_newest_element.png
Received on Thursday, 15 August 2013 21:35:59 UTC