- From: Tom Van Eetvelde <tom.van_eetvelde@alcatel.be>
- Date: Mon, 09 Oct 2000 11:08:25 +0200
- To: www-rdf-interest@w3.org
- Message-ID: <39E18B09.1E7A8C2E@alcatel.be>
Dear RDF comunity,
After working for a while with RDF, I start to question some of its aspects. First of all: "why were
Literals ever introduced?" and secondly, "Why is there a special RDF syntax, why no DTD?".
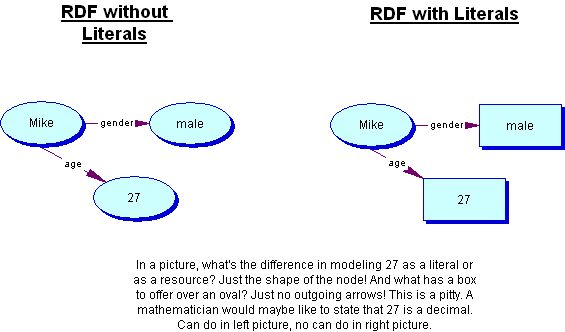
Why literals in RDF?
First of all, when you look at the philosophy of RDF, you need to be able to tell anything about
anything. When I use Literals in my RDF documents, nobody is able to elaborate on them as Literals
may not be referred to. This is a bit strange.
Currently, Literals are items you are not allowed to say anything about. One could issue that
Literals are like the atomic buidling blocks of an OO model: OO builds on characters, decimals, ...
datatypes which do not belong to the OO model. They are needed to bootstrap the OO model. Still,
this viewpoint on Literals doesn't hold.
The reason is that Literals do not contribute anything to the RDF model. On the contrary, they
introduce restricitons (no arrows may origine in Literals) that are against the RDF model
philosophy. And this while literals are not really needed! They just make you step out of your
trippel model. The Literals that I use in my application domain could be resources modelled in
another application domain. If you ask me, get rid of the Literals in the RDF model. When you take a
graphical example, it only makes it clearer (see attachment).
Why not using DTD's to support serializing RDF?
Take a look at following DTD:
<!ELEMENT graph (arc)*>
<!ELEMENT arc (node, link, node)>
<!ELEMENT node>
<!ELEMENT link>
<!ATTLIST node id ID #optional>
<!ATTLIST link id ID #optional>
This XML DTD supports making RDF (directed labeled graph) instances. If you want to add namespacing,
add attributes to the graph element. The id's used have to follow the URI conventions.
I think the DTD reflects the RDF model completely if you throw away the literals (which I never use
as I do not find them useful): resource, propertyl, resource. It has everything to support writing
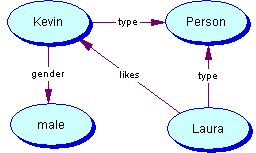
down tripples. Simpel RDF instance example:
<graph>
<arc>
<node id="Kevin"/>
<link id ="rdf:type"/>
<node id="s:Person"/>
</arc>
<arc>
<node id="Kevin"/>
<link id ="s:gender"/>
<node id="male"/>
</arc>
<arc>
<node id="Laura"/>
<link id ="rdf:type"/>
<node id="s:Person"/>
</arc>
<arc>
<node id="Laura"/>
<link id ="s:likes"/>
<node id="Kevin"/>
</arc>
</graph>
Parsing this graph (and validating it to make sure a graph is written down) is piece of cake. I do
not understand why so much effort has been put in RDF XML serialization syntax. RDF = a tripple
model. As soon as you are able to write down tripples and URI's, the serialization is OK, right?
I believe this format is easy enough to be read by humans (for parser debugging, ...), but most of
all: it is ideal for machines. As I said before (see previous mail in newsgroup): people should not
be editing in ASCII format. Simply draw a picture (see attachment) and let the machine convert to
ASCII format. I guess the picture is clearer then any serialization syntax.
Is there something I forgot about the RDF model that is impossible to introduce in this syntax?
------
I would be happy to receive reactions on both subjects as this can only improve my insight in RDF.
Greetings,
Tom.
Attachments
Received on Monday, 9 October 2000 05:10:14 UTC