- From: Butler, Mark <Mark_Butler@hplb.hpl.hp.com>
- Date: Mon, 26 Jan 2004 19:23:56 -0000
- To: " (www-rdf-dspace@w3.org)" <www-rdf-dspace@w3.org>
- Message-ID: <E864E95CB35C1C46B72FEA0626A2E808ED21A8@0-mail-br1.hpl.hp.com>
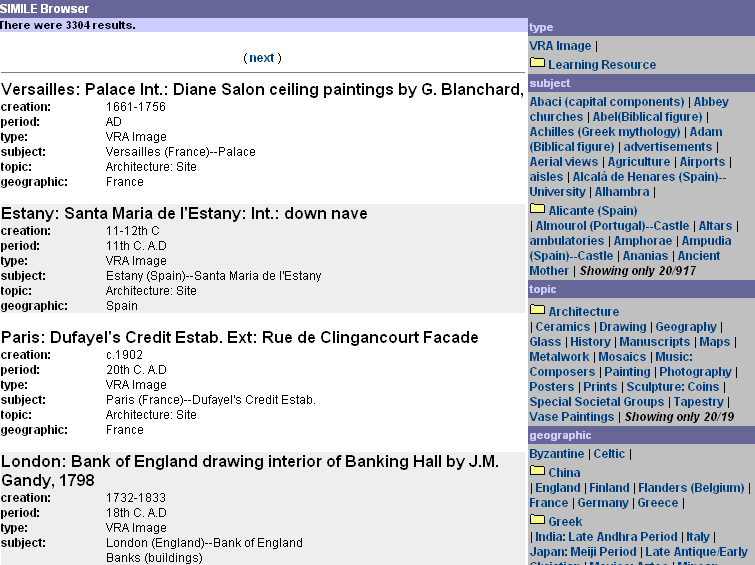
Hi team, A while back we agreed that in an ideal world, there are three stages to the demo: 1) browse and query a subset of the Artstor and the OCW data 2) browse and query the entire Artstor and OCW data from a local persistant store 3) browse and query the entire Artstor and OCW data from a HTTP based store At the telecon last week, I stated that I think 3 may be difficult in the timescale of the demo. I want to explain exactly why this and then discuss the implications of this for the demo. BACKGROUND Hopefully by now other people will have had a chance to download the custom browser prototype, which I have named "Longwell" from CVS. Early versions of Longwell used Lucene to index and query data, but I've now finished a version of Longwell that uses a mixture of RDQL and Jena to query the data. I want to explain the process that Longwell uses to query the data and the implications of this for 3. I'm guessing that Vineet's faceted browser in Haystack must work in a similar way, so these points may also be relevant to Haystack although perhaps Vineet can explain how his browser works. Longwell is a faceted browser, so its UI is configured with three bits of information - see ArtstorRepository.java: - the types of the RDF data objects to display (for example vra:Image and lomEdu:learningResourceType) - which fields to display (a field is a property with a literal value) - which facets to display (a facet is a property that points to a controlled term represented by another RDF data object) Its UI consists of two separate elements (see the enclosed image): - the results set (the left hand pane) of all the data objects that match the current set of facet restrictions - a facet navigator (the right hand pane) that lists the current restrictions along with further restrictions which may be placed on the results set Longwell creates the UI in three stages: - First it queries the data to identify the URIs of all the resources corresponding to data objects that belong to registered types and match the current restrictions. - Then it builds the result set using a subset of these URIs - initially the results 1 to 10 although the user can page through the results set - and queries all the registered fields and facets in order to generate the results set. Some of these fields and facets can have multiple values e.g. London: Bank of England drawing interior of Banking Hall by J.M. Gandy, 1798 creation: 1732-1833 period: 18th C. A.D type: VRA Image subject: London (England)--Bank of England Banks (buildings) financial buildings banking halls Drawing topic: Architecture: Artist geographic: England creator: Soane, Sir John,1753-1837 - Then it builds the facet navigator by querying the facet values for the entire results set, to build a list of unique facet values for each configured facet type e.g. Topic: Architecture | Ceramics | Drawing | Geography | Glass | History | Manuscripts | Maps | Metalwork | Mosaics | Music Composers | Painting | Photography | Posters | Prints | Sculpture: Coins | Special Societal Groups | Tapestry | Vase Paintings Geographic: Byzantine | Celtic | China | England | Finland | Flanders (Belgium) | France | Germany | Greece | Greek | India: Late Andhra Period | Italy | Japan: Meiji Period | Late Antique/Early Christian | Mexico: Aztec | Minoan (Knossos) | Netherlands | Palaeolithic | Portugal | Prehistoric Currently Longwell does not calculate frequency of occurrence as Vineet's browser does but this is on the "to do" list. COMPARING RDQL / JENA with LUCENE / JENA Currently Longwell takes 1142 ms to perform stages 1, 2 and 3 at worst case i.e. no restrictions for 3300 records which is 1/34 of the entire dataset when querying an in memory model. Task manager indicates Longwell takes 130 megabytes of ram. We can therefore extrapolate likely performance for the entire Artstor dataset: assuming we had a machine with enough ram (say 5 GB), and Java could deal with that amount of memory (which it might not, I remember Nick talking about this when I was in Boston) it should take around 40 seconds for worst case. If we assume a ten fold slow down for a persistant model, then we are talking of the order of minutes. I'm guess that querying via HTTP could potentially add another ten fold slowdown here. Interestingly, RDQL/Jena do compare favourably against Lucene e.g. Jena / Lucene Jena / RDQL Time to read in data and schemas 37000 ms 37000 ms Time to build index 52000 ms 0 ms Worst case time to build UI 1582 ms 1142 ms although I suspect I'm not giving Lucene the chance to cache indexers so I need to check my code. ISSUES WITH USING RDQL OVER HTTP Now I am still getting to grips with RDQL so perhaps Andy can correct me if I am wrong but seems to me there are a number of potential difficulties in implementing the three stages used in Longwell via RDQL over HTTP: a) In stage 1 we create x RDQL queries, where x corresponds to the number of registed object types (unless we have a query that contains an type constraint) e.g SELECT ?a WHERE (?a, p1, v1), (?a, p2, v2), ... (?a, pn, vn), (?a, rdf:type, vra:Image) SELECT ?a WHERE (?a, p1, v1), (?a, p2, v2), ... (?a, pn, vn), (?a, rdf:type, lomEdu:LearningResourceType) Where p1 ... pn are the properties and v1 ... vn are the values in the restrictions. For example, to create the initial results set, we use the queries SELECT ?a WHERE (?a, rdf:type, vra:Image) SELECT ?a WHERE (?a, rdf:type, lomEdu:LearningResourceType) Now this is fine when querying a local store, but when querying over HTTP the most efficient way to get the results is a list of resources rather than a subgraph, as the subgraph will be of the form a p1 v1 ; p2 v2 ; ... pn vn ; rdf:type vra:Image . i.e. will mainly consist of information we already have. Does Joseki provide a way to just retrieve resources, or does it return the subgraph? Better still, we may not want to retrieve this results set at all, as it is intermediate computation so it is better to keep it on the server to use it as the basis for queries corresponding to stages 2 and 3. b) In stage 2, we have to query each property corresponding to a field or facet individually for a subset of the results set acquired in the previous stage. The individual bit is important because the properties may not exist, so if we query all the properties concurrently then will only get the objects that correspond to subjects that have all the properties when we actually want objects that correspond to subjects that also have a subset of the properties. This creates a problem when quering over HTTP as we want to minimize the number of queries, so really we want to query these properties in a single query that can express these properties are optional rather than constraining. Dave Reynold's paper on QBE http://www.hpl.hp.com/semweb/publications/DaveR-www2003.pdf discusses the use of predicate patterns to solve this problem, and I guess they can be used in RDQL as it supports REGEX expressions, but ideally using namespaces in this way is not sufficiently specific as we want to specify a subset of properties corresponding to the descriptive metadata and omit the technical metadata. Second here the query processor must return subgraphs otherwise we will potentially have problems with properties with multiple values as Dave Reynolds describes in section 2.1.1 of the QBE paper. Third, as far as I know, RDQL does not provide functionality similar to cursors so it is not possible to retrieve a subset of the results set. Nor does it provide functionality similar to sort by, so providing cursors is potentially meaningless as in Jena there is no guarantee about statement ordering in models, so the ordering of results sets may vary between subsequent queries. c) In stage 3, we have the same problems of having to query facets individually and multiple values for the same property. Note stage 3 is much more critical than stage 2, as in stage 2 we just work on a fixed size subset of the results set whereas in stage 3 we work across the entire results set, so at a minimum the time taken to calculate stage 3 will increase linearly with the size of the dataset. In addition, as we are interested in summary statistics rather than every individual facet value, it would be useful to have a mechanism similar to count in SQL so we just get back unique facet values and their frequency. I spoke to Andy about this a while ago, and he suggested precomputing the frequencies of the facet values. Unfortunately precomputing in this way won't help when processing restrictions as the frequencies of available facets changes dependant of the restrictions currently in force i.e. we have to recalculate. The worst possible case for calculating facet values is when no restrictions are in place, and the majority of restrictions drastically partition the dataset, so there may still be some advantage in precomputing frequencies for this worst-case situation. SUMMARY So in summary it is not clear whether RDQL will support a number of things that we would like: - cache intermediate results on the server, and use them as the basis of further queries. - distinguish between predicates that must be matched and predicates that are optional. - whether it is clever enough not to return information which is implicit in the queries. - some way to sort results so we can guarantee ordering. - retrieving results subsets (cursors in SQL). - some to count the number of times that a data object is the object of a particular property. WORKAROUNDS Clearly this is a lot of work to do in time for the demo but I would like to propose a number of workarounds, and I would be interested to hear other suggestions: 1. We could have a browser that does not support a faceted navigation pane. This will impact user functionality, because as we've discussed before providing a summary of the collection as a faceted navigation pane makes it much easier for the user to query collections that they are unfamiliar with. However it may simply not be feasible to use facted navigation above a certain dataset size. 2. Currently Longwell consists of a servlet with a Velocity template which serves results as HTML. It would be possible to create another Velocity template that served results as RDF/XML, and as Longwell uses query strings to describe restrictions this provides the basis of a specialized query API. It would be fairly straightforward to return the results set as RDF, but returning the faceted navigation pane would require the creation of a small schema / ontology. This approach is very specialized, but will be much more efficient in its use of HTTP than implementing the queries as step-by-step HTTP requests as outlined above. Alternatively we could have a single template that created XML, and then XSLT to style that to HTML or RDF/XML. 3. We could also (or additionally) provide an RDQL query API by giving Joseki access to the model used by Longwell, so although the HTML interface is being generated on the server, this does not preclude the use of RDF/XML SW-enabled APIs. Any other suggestions? Feedback? Thanks are due to Dave Banks for discussing these issues with me. Mark Butler Research Scientist HP Labs Bristol http://www-uk.hpl.hp.com/people/marbut
Attachments
- application/octet-stream attachment: longwell1.png
{kind=link}
Received on Monday, 26 January 2004 14:29:22 UTC