- From: Axel Polleres <droxel@gmail.com>
- Date: Fri, 11 Mar 2016 08:59:00 +0100
- To: Wouter Beek <w.g.j.beek@vu.nl>
- Cc: Jean-Claude Moissinac <jean-claude.moissinac@telecom-paristech.fr>, Luca Matteis <lmatteis@gmail.com>, Pierre-Antoine Champin <pierre-antoine.champin@liris.cnrs.fr>, Semantic Web <semantic-web@w3.org>, Paul Groth <p.groth@elsevier.com>
- Message-Id: <07FF7C51-83D2-4470-98DD-D89308DFB1AF@gmail.com>
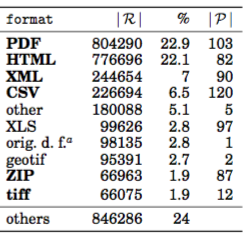
Hi Wouter, > - Should we still promote SPARQL when we know that it so fundamentally breaks the Open Data agenda? I don't agree here... > - SPARQL is ATM not a viable dissemination strategy for Open Data ... > - LDF is a viable dissemination strategy for Open Data ... My firm opinion is you need a mix of direct and replicated data access. Also, what you mention - "arbitrary result sizes" - is not a problem of SPARQL per se, but a probably missing feature for sparql endpoint-description. [1] There are ways around restrictions. And there are tools which serve one purpose but not the other ind vice versa (dumps vs. SPARQL endpoints), it is wrong IMHO to call one of them the 'right' and one of them the 'wrong' dissemination strategy without further differentiation, right? Besides, the vast majority of Open Data is neither available as LDF nor as SPARQL endpoints, because it is simply not RDF (and it is arguable whether translating it into RDF is the right strategy), cf. this plot about Data format prevalence from over 260 Open Data portals we monitor at http://data.wu.ac.at/portalwatch ... Mainly documents (not surprising), but among structured formats there's still far more XML and CSV data out there than RDF. Plus, this data is partially changing *very* frequently (we observe dynamicity in Open Data - also not surprisingly - increasing), defnitly more frequently than crawling and packaging up ad LDF could cope with. Opinions? just my 2, Axel 1. Carlos Buil Aranda, Axel Polleres, Jürgen Umbrich: Strategies for Executing Federated Queries in SPARQL1.1. International Semantic Web Conference (2) 2014: 390-405 -- url: http://www.polleres.net/ twitter: @AxelPolleres > On 11 Mar 2016, at 08:20, Wouter Beek <w.g.j.beek@vu.nl> wrote: > > Hi, > > Let me summarize this conversation: > > - Person asks how to obtain Linked Open Dataset. > - Solution 1: SPARQL "appears to have some kind of 'throttling' preventing to get exhaustive results". > - Solution 2: LDF "I can't seem to extract the dump, but you can crawl it all you want". > - Solution 3: Datadump "Just click this link". > > My take on this: > > - SPARQL is ATM not a viable dissemination strategy for Open Data since it introduces arbitrary barriers to result set size. The first requirement on any Open Data dissemination strategy should be that it is at least possible to obtain the full data. > - LDF is a viable dissemination strategy for Open Data since it allows low-level queries to be asked without sacrificing openness the way SPARQL does. However, downloading all the data potentially requires many HTTP requests since data is segmented in relatively small pages (a very common approach in Web APIs). > - Datadumps are inferior to LDF (no triple pattern queries) but superior to SPARQL endpoints (all data can be retrieved). They are also superior to LDF for the singular use case of obtaining all the data. > > My questions for the community: > > - Should we still promote SPARQL when we know that it so fundamentally breaks the Open Data agenda? > - Could LDF be improved to handle the "just give me all the data" use case better? I'm thinking of being able to open LDF results in a continuous gzipped stream i.o. separate pages. > > --- > Best, > Wouter Beek. > > Email: w.g.j.beek@vu.nl > WWW: wouterbeek.com > Tel: +31647674624 > > On Thu, Mar 10, 2016 at 10:39 PM, Jean-Claude Moissinac <jean-claude.moissinac@telecom-paristech.fr> wrote: > There is also an archive here for the triples from 2009 on http://www.cs.toronto.edu/~oktie/linkedmdb/ > > > Cet e-mail a été envoyé depuis un ordinateur protégé par Avast. > www.avast.com > > -- > Jean-Claude Moissinac > > > 2016-03-10 22:22 GMT+01:00 Luca Matteis <lmatteis@gmail.com>: > I have a Linked Data Fragments version running here http://hdt-gae.appspot.com/ > I can't seem to extract the dump, but you can crawl it all you want > since LDFs have no throttling ;) > > On Thu, Mar 10, 2016 at 8:48 PM, Pierre-Antoine Champin > <pierre-antoine.champin@liris.cnrs.fr> wrote: > > Hi SemWeb people, > > > > I'd like to run a local version of LinkedMDB [1], but it seems that only the > > SPARQL endpoint is still running, the wiki and the dump [2] are down. > > > > Would anyone have a backup of the dump? > > > > NB: before anyone suggests that: it can't be easily extracted from the > > SPARQL endpoint, which appears to have some kind of "throttling" preventing > > to get exhaustive results on very "open" queries... > > > > [1] http://data.linkedmdb.org/ > > [2] > > https://datahub.io/dataset/linkedmdb/resource/dd7619f9-cc39-47eb-a72b-5f34cffe1d16 > > >
Attachments
- text/html attachment: stored
- image/png attachment: Screen_Shot_2016-03-11_at_08.54.02.png
Received on Friday, 11 March 2016 07:59:33 UTC