- From: Francois Yergeau <FYergeau@alis.com>
- Date: Thu, 09 Jan 2003 16:28:34 -0500
- To: ietf-charsets@iana.org
- Message-id: <F7D4BDA0E5A1D14B99D32C022AEB7366A50754@alis-2k.alis.domain>
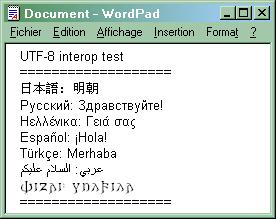
Well, Take 2 was completely destroyed by an early click on the wrong button, so let's try again. Sorry for the noise. ----------------- This message is the initial part of a test of Take 3 of interoperability of UTF-8 on the Internet. The reason for having a new test is that the initial round did not test any characters beyond the BMP (character number > 0xFFFF). The test is based on a test file of plain text encoded in UTF-8, containing text in a few languages and scripts. The test file was composed in Windows 2000 Notepad and is attached to this message as test-utf-8bis.txt. It has an initial BOM (Byte Order Mark). The content of the test file, copy-pasted into this message is: ------------------>snip<--------------------- UTF-8 interop test =================== 日本語: 明朝 Русский: Здравствуйте! Ηελλένικα: Γειά σας Español: ¡Hola! Türkçe: Merhaba عربي: السلام عليكم 𐌸𐌹𐌶𐌰𐌹: 𐍅𐌿𐌻𐍆𐌹𐌻𐌰 =================== ------------------>snip<--------------------- Also attached is test-utf-8bis.jpg, a JPEG screen shot showing the test file in Windows 2000 Wordpad. Wordpad is used here because Notepad allows only a single font for the whole file, which is insufficient as I do not have a single font containing glyphs for all the scripts in the test file. To get correct display in Wordpad, it is sufficient to set an adequate font (James Kass' Code2001 here) on the last line, which is in the non-BMP Gothic script). Also attached is test-utf-8bis.html, an HTML version of the same text. Instead of a BOM, this version uses a <meta> element to identify the charset as UTF-8. An interop report will follow as a reply to this message. -- François Yergeau
Attachments
- text/plain attachment: test-utf-8bis.txt
- image/jpeg attachment: test-utf-8bis.jpg
- text/html attachment: test-utf-8bis.html
Received on Thursday, 9 January 2003 16:30:15 UTC