Author: Sean B. Palmer; Date: 2002-02; for WAI PF and wider discussion.
The XML Accessibility Guidelines discuss semantics and syntax, with emphasis on exporting and documenting semantics as much as possible. However, techniques for this are lacking, due to the deficiencies of the schema languages for XML.
This document is a strawman proposal for enabling people to not only identify markup constructs as first class objects on the Web, but to be able to identify them as members of a certain semantic type, and link those types together in a Web of logic; to apply a strict semantics to not just properties and classes flying about in the RDF world, but to XML document trees and markup idioms too.
In XAG, we talk about semantics a lot - and particularly the binding of
semantics to the syntax. In fact, the binding is often implicit, and the fact
that the purpose of XML is often other-than to frame and hang in an art museum
contributes to this. The problem is that the "semantics" of an markup construct
is very difficult to capture. For example, <p> in HTML is
supposed to be a "paragraph", but the actual meaning of a paragraph for
many people is dependent upon years of studying language forms - of associating
line breaks and indentations (or pauses, to be less media dependent) to this
particular concept.
This introduces a severe problem for accessibility. It's a showstopper in many cases. The problem, as hinted at above, is that semantics and syntax are inseparably bound, and often dependent upon media. For many browsers, an HTML blockquote tag [sic] means "indent the next bit of text here". Because of that, people may confuse the syntax for the semantics.
But O.K., we know this is a problem. We want to fix it.
Before we do, we should take a look at another blatant case of syntax/semantics confusion; that of XML Schema. In XML Schema, there are a certain amount of constructs that give the impression of semantic association. For example, there's the humble substitution group:-
<xsd:element name="title" substitutionGroup="u:annotation"/> <xsd:element name="summary" substitutionGroup="u:annotation"/> <xsd:element name="description" substitutionGroup="u:annotation"/>
You would think that this implies that the title, summary, and description elements share some common semantics, but remember that XML Schema is a schema language for syntactic validation only. To quote the XML Schema primer (slightly out of context) about the substitution group construct, "[it] simply provides a mechanism for allowing elements to be used interchangeably."
"Decentalization" and "grounding semantics in the Web" are cliches, but for a good reason. As stated before, the semantics behind particular markup constructs vary over the contexts in which they are created, used, and otherwise interpreted. With the Web, we have the real opportunity to create some semblance of a shared context - we can agree to use terms without any one particular group dictating what will be.
With the introduction of XML namespaces, it made many buzzwords possible (for each new acronym created, at least ten buzzwords appear); decentralization, evolution, transformability. One of the key technologies for connecting the semantics of each language together is RDF. In fact, the various serializations of RDF are not important, but the model is.
What we are working towards is being able to not only identify markup constructs as first class objects on the Web, but to be able to identify them as members of a certain semantic type, and link those types together in a Web of logic.
The point of this is that it makes the XAG conformance criteria automatable to some extent. For example, take checkpoint 1.1: Provide a mechanism to explicitly associate alternative equivalents for content or content fragments. To test conformance to this checkpoint, you need to know the following:-
When the latter is used on the former, you pass the test. You also need to know what qualifies as "use".
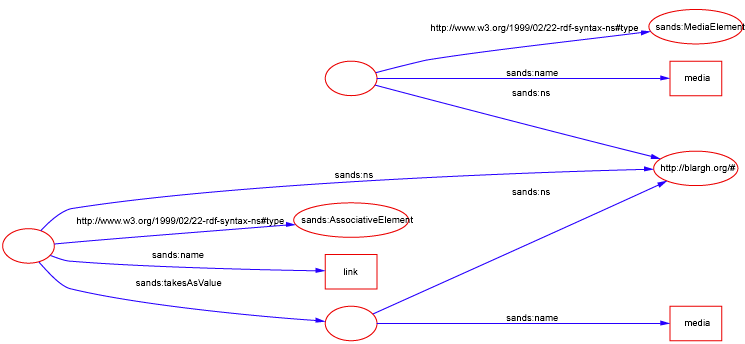
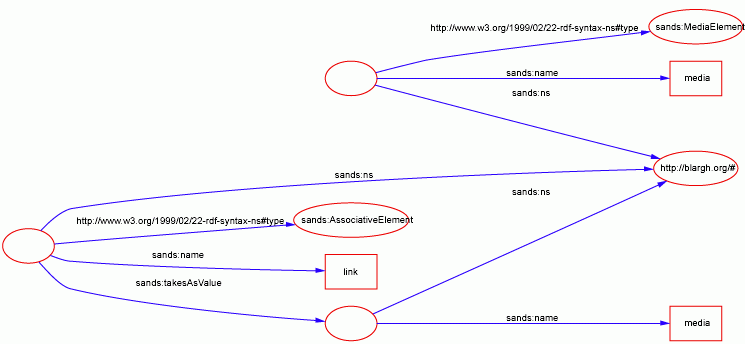
For example, let's say that we have a media element, and a link element for linking bits of media together:-
[ a :MediaElement; :ns <http://blargh.org/#>; :name "media" ] . [ a :AssociativeElement; :ns <http://blargh.org/#>; :name "link"; :takesAsValue [ :ns <http://blargh.org/#>; :name "media" ] ] .
It is achingly clear that this passes XAG checkpoint 1.1 to some extent. The syntax used above may not, however, be clear. It is a mixture of semantics and syntax. The nearest DTD equivalent is:-
<!ELEMENT media [...] > <!ELEMENT link (media+) >
The "ns" and "name" predicates simply create a QName of the subject. The rdf:type (keyname: a) predicate relates the type of the QName, remembering that a QName is more than just a bit of syntax: it is actually a block of a language. In this case, we can actually give the semantic types of the elements. That's quite neat in itself.
But there is more at play here: the "takes as value" predicate associates the the subject QName with the object QName under constraint of the types of the QNames involved. In other words, in this case, we may define that when an element of type "AssociativeElement" takes as value an element of type "MediaElement", syntactically the value can occur 1 or more times inside the subject element, and that semantically, all instances that occur are somehow bonded together (i.e., this is the nature of an associative element).
I hope that's clear. We're giving people their semantics back, and making sure that this is all testable. For example, one can now write a FOPL rule such that:-
{ [ is log:semantics of <MySchema.rdf> ]
log:contains { [ a :MediaElement ] };
log:notContains { [ a :AssociativeElement;
:takesAsValue [ a :MediaElement ] ] } } log:implies
{ this earl:asserts
[ rdf:subject [ is log:semantics of <MySchema.rdf> ];
rdf:predicate earl:fails;
rdf:object <http://www.w3.org/TR/2001/WD-xmlgl-20010829#cp1_1> ] } .
There are many element types that evolved by consensus. XAG talks about "element types that allow classification and grouping (header, section, list, etc)". Elements for navigation with well-defined roles are also good examples.
What is a good XHTML-like language made up of?
For example XHTML is a semantic and syntactic language composed of various (syntactic) modules. The types of each element and markup construct may be allied closely to its particular module, or there may also be some cross module relationships. In fact, although XML is necessarily hierarchial, there is no for the semantics of the elements to be closely hierarchial.
By means of analogy, HTTP is (or was, orginally) based upon a folder-hierarchial model, but HTML allowed one to break free. There is no reason why our languages shouldn't be allowed to do the same.
Sticking to the XHTML example, we can apply some rules to three of the modules therein:-
@prefix : <#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix w3c: <http://www.w3.org/1999/> . @prefix h: <http://www.w3.org/1999/xhtml#element.> . [ a :Module; :title "Link Module"; :containsElements (h:link) ] . [ a :Module; :title "Metainformation Module"; :containsElements (h:meta) ] . [ a :Module; :title "HyperText Module"; :containsElements (h:a) ] . h:link a :AssociativeElement; :ns w3c:xhtml; :name "link"; :associativeSubjectType :Document; :associativeObjectType :Resource . h:meta a :AssociativeElement; :ns w3c:xhtml; :name "meta"; :associativeSubjectType :Document; :associativeObjectType :Literal . h:a a :AssociativeElement; :ns w3c:xhtml; :name "a"; :associativeSubjectType :TextSpan; :associativeObjectType :Resource .
Because the semantics of the markup constructs have been exposed, it is possible to generate default stylesheets (per XAG checkpoint 3.1: provide default style sheets for multiple output modalities where possible) given the semantic characteristics of the elements. For example, it is a customary style for associative elements that have a text span as subject to be styled as blue underlined text. Here is a rule for generating a CSS stylesheet:-
{ ?x a :AssociativeElement; :ns ?y; :name ?z;
:associativeSubjectType :TextSpan .
("@namespace ns url(" ?y ");\n"
"ns|" ?z " { color: blue; text-decoration: underline; }") string:concat ?p }
log:implies { :x log:outputString ?p } .
Applying that to the XHTML example above gives:-
@namespace ns url(http://www.w3.org/1999/xhtml);
ns|a { color: blue; text-decoration: underline; }
To mix syntactic and semantic schemata, we need to be able to identify QNames as first class objects on the Web. Unfortunately, there are issues with namespace structures and identification. However, we can outline the process of identifying a QName (using a technique example from XAG 2.6).
First, we have some simple type declared in XML Schema:-
<xsd:simpleType name="ISBNType">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\d{5}-\d{5}-\d{5}"/>
<xsd:pattern value="\d{1}-\d{3}-\d{5}-\d{1}"/>
<xsd:pattern value="\d{1}-\d{2}-\d{6}-\d{1}"/>
</xsd:restriction>
</xsd:simpleType>
the QName for this SimpleType may be as follows:-
[ a xsd:SimpleType; :ns ""; :name "ISBNType" ] .
in fact, it may be possible to map the whole thing to RDF:-
[ a xsd:SimpleType; :ns ""; :name "ISBNType";
xsd:restriction [ xsd:base xsd:string;
xsd:pattern "\d{5}-\d{5}-\d{5}",
"\d{1}-\d{3}-\d{5}-\d{1}",
"\d{1}-\d{2}-\d{6}-\d{1}" ] ] .
XML Schema processors have to keep track of the QName and the type, although there may no be a standard for doing that. Merging XML Schema and RDF may be possible even though the documents are separate. Indeed, the XML Schema may contained within some RDF:-
<> :xsdFragment
"""[...]
<xsd:simpleType name="ISBNType">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\d{5}-\d{5}-\d{5}"/>
<xsd:pattern value="\d{1}-\d{3}-\d{5}-\d{1}"/>
<xsd:pattern value="\d{1}-\d{2}-\d{6}-\d{1}"/>
</xsd:restriction>
</xsd:simpleType>
[...]""" .
Of course, there are plenty of issues - from the social (who will take care of a sands schema, if at all?) to the technical (how do we model QNames?). There is probably not enough drive space on the W3C machines to discuss these things to resolution, but I hope that won't stop us from trying.
Development of such a schema, and the infrastructure required to process it, would be tricky. There are many things to be considered - for example, it occured to me that MediaElement in the examples above is really a subClassOf AssociativeElement, in that it associates a piece of media with a base in the document. cf. xlink:show="embed".
In general, there are many types of elements in XML. In XAG and elsewhere, elements such as the following are declared:-
Clearly, this is a highly document-oriented view, at the moment. I don't believe that it has to be bound to that in particular, although I think that XAG is oriented towards that.
This work is related closely to some of the issues that TAG have been chartered to address. One of Tim's DesignIssues documents contains the following seminal verbiage:-
On the Web, important things are identified by URIs. This should clearly apply both to the document itself and to the language. [...]
In XML, a language is a "namespace", and the document about the language is called a "schema". In XML, one document can contain a mixture of languages, and so the schema if written in XML may contain information about syntactic constraints (in XML-schema language) and/or RDF properties (in rdf-schema language), or any combination of the above. [...]
We can say a document is "grounded" if its meaning is completely defined because every term used is explicitly, directly or indirectly, an explicit direct or indirect referece to its definition in a document on the Web.
Another very interesting piece (which I had actually overlooked to some extent until now) is "Schema option 6: Expose logic of document" in The Evolution of a Specification. This says that defining the logic behind a particular language is more interesting in the long run that simply defining a bit of structure and then letting documentation and APIs deal with the semantics. It seems to be aimed at RDF languages rather than XML languages. The aim of this document then is made clearer: to apply a strict semantics to not just properties and classes flying about in the RDF world, but to XML document trees and markup idioms too. Forms of this have been suggested before on a lesser scale: I seem to recall ideas of annotating certain parts of an XML Schema document with RDF.
Another crucial piece of the puzzle is RDDL: a document format based on XHTML and XLink that provides a method of associating various schemata (both semantic and syntactic) with a namespace. To wit:-
A Resource Directory provides a text description of some collection of resources and of individual resources related to that collection. It also contains a directory of links to these related resources. An example of a "collection of resources" is that defined by an XML Namespace. Examples of "individual related resources" include schemas, stylesheets, and executable code.
Credit is also due to Aaron Swartz, for nearly implementing a system that is rather reminiscent of this one. The proposal included a new schema type that identified elements in class hierarchies, and document instances that linked to RDF extensions of their defining schemata:-
<doc xmlns:foo="http://example.net/foo/"
xml:lang="en" >
<head>
<extension ns="foo" def="foo.n3" type="application/rdf+n3" />
</head>
</doc>
"Tell 'em what you told 'em".
Formalizing semantics has recently got a lot of press through RDF and the Semantic Web, and yet these principles have not really been applied to XML. It is about time that they were.
Well, just about everyone. This idea is by no means new. Aaron Swartz, Tim Berners-Lee, and Jonathan Borden are amongst the people that have had the same idea, and inspired this document.
Sean B. Palmer2002-02. Validate me
{kind=link}
{kind=link}
{kind=link}