The basic difficulty in providing this software support is that the Web was originally aimed at providing its resources to people, not to other software, and so Web resources do not have descriptions of their meanings or capabilities that software can understand. For example, the meaning of a Web page is determined by human understanding of the screen content when the page is displayed in a browser. This meaning is inaccessible to a piece of software. As a result, software such as search engines must rely on such techniques as simple text matching, rather than being able to process Web resources based on an understanding of their true relationships to a user's intentions and needs.
The Semantic Web is going to change all that. The Semantic Web will enhance the Web's inter-linked information and service resources with software-interpretable descriptions of the resources' meanings, capabilities, and inter-relationships. These descriptions will allow tools such as agents, search engines, or service brokers to more automatically and reliably find and use appropriate resources in response to user requirements. At the same time, the Semantic Web creates the infrastructure for entirely new classes of agent-oriented capabilities. @@need some discussion of these other capabilities; also want to refer to apps involving non-Web resources
The W3C’s Resource Description Framework (RDF) is, as its name suggests, a framework (or approach) for describing Web resources. The approach is based on some very simple ideas, but when those ideas are taken together, and suitably generalized (as they are in RDF), they provide a means for describing practically anything, in a form that can be processed by software. The use of RDF (and richer approaches based on it) provides the basic technology for providing the software-interpretable descriptions required to support the Semantic Web.
At the same time, the use of RDF does not necessarily involve the use of inference, logic programming, or related technologies, as the term “semantic” might suggest. RDF also provides essential support for applications such as providing simple information about Web content (provenance, content ratings), defining privacy policies, specifying site maps, or supporting description-based Web service brokering.
@@Editorial notes: this
version addresses various comments (mostly by Pat) on the original version,
and preserves the original order of topic presentation.
There have been some suggestions to move the description of URIs to the beginning,
and then talk about Ntriples and graphs ("pure RDF"). A problem with
that approach is that I think a primer on RDF ought to start off talking about
RDF's general approach to describing things in terms of subjects, properties,
and their values, rather than a discussion of how to identify things (in
particular, the use of URIs to name properties doesn't have much significance
until you talk about what a property is). I've got a version in the
works that presents part of "The General Idea", then does the URI stuff,
and then gets into triples, but the URI section is a major interruption to
what I believe is the natural flow of the text (at least to someone with
a database or other non-Web background).
Anyway, we'll see.
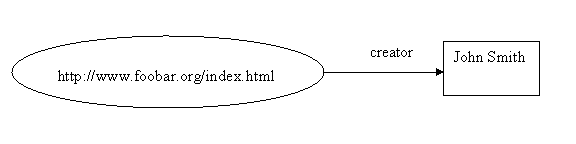
“the creator of [the particular Web page we’re talking about ] is John Smith “
We’ve underlined parts of this statement to illustrate that, in order to describe the properties of something, we need ways to identify a number of things:
“the creator of http://www.foobar.org/index.html is John Smith“
In this statement, in addition to using a URL to identify the Web page, we’ve used the word “creator” to identify the property we want to talk about, and the two words “John Smith” to identify the thing (a person) we want to say is the value of this property.
We can state other properties of this Web page by writing additional English statements of the same general form, using the URL to identify the page, and words (or other strings) to identify the properties and their values. For example, to specify the date the page was created, and the language in which the page is written, we could write the additional statements:
“the creation-date of http://www.foobar.org/index.html
is August 16, 1999“
“the language of http://www.foobar.org/index.html
is English “
(note the use of the string "August 16, 1999" to identify a date).
RDF assumes as its basic model that things have properties which have values, and that resources can be described by making statements, similar to those above, that specify those properties and values. RDF uses a particular terminology for talking about the various parts of statements. Specifically, the part that identifies the thing the statement is about (the Web page in this example) is called the subject . The part that identifies the property or characteristic of the subject that the statement specifies (creator, creation-date, or language in this case) is called the predicate, and the part that identifies the value of that property is called the object. So, taking the statement
“the creator of http://www.foobar.org/index.html is John Smith“
in RDF terminology:
RDF statements are similar to a number of other formats for recording information, such as:
RDF represents statements as nodes and arcs in a graph. In this notation, a statement is represented by a node for the subject, a node for the object, and a labeled arc between them for the predicate, as in:
Figure 1
Collections of statements are represented by corresponding collections of nodes and arcs. So the three statements we’ve given so far would be represented by the following graph:
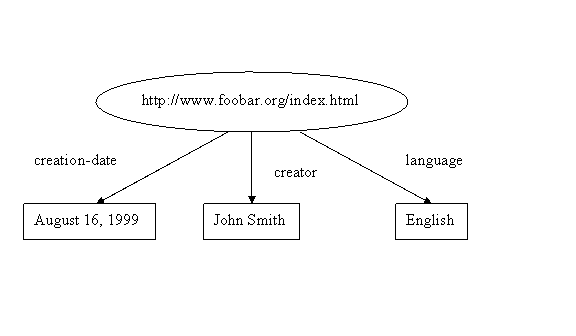
Figure 2
The graph is technically a labeled directed graph, since the arcs have labels, and are “directed” (point in a specific direction, from subject to object).
Sometimes it is not convenient to draw graphs, so an alternative way of writing down the statements, called triples, can be used. In the triples notation, each statement in the graph is written as a simple triple of subject, predicate, and object, in that order. The triples representing the above three statements would be written:
<http://www.foobar.org/index.html> creator
"John Smith"
<http://www.foobar.org/index.html> creation-date
"August 16, 1999"
<http://www.foobar.org/index.html> language
"English"
Each triple corresponds to a single arc in the graph, complete with the arc’s beginning and ending nodes (the subject and object of the statement). Unlike the drawn graph, the triple notation requires that a node be separately identified for each statement it appears in. So, for example, http://www.foobar.org/index.html appears three times (once in each triple) in the triple representation of the graph, but only once in the drawn graph.
In each of the statements we’ve considered so far, the object has been a simple string (e.g., we've used “John Smith" to identify a particular person, and "August 16, 1999" to identify a particular date). In RDF, the objects in statements may be any kind of string. More importantly, the objects in RDF statements may also be the URLs of other Web resources. This allows us to represent not only the properties of individual resources, but also relationships between those resources and others. So, for example, we could represent the fact that the resource at http://www.barbaz.org/myprojects.html has the same creator as the resource at http://www.foobar.org/index.html by the statement
<http://www.foobar.org/index.html> sameCreatorAs <http://www.barbaz.org/myprojects.html>
And we could represent the fact that the resource at http://www.foobar.org/index.html links to the resource at http://www.w3.org/ by the statement
<http://www.foobar.org/index.html> linksTo <http://www.w3.org/>
Adding these two additional statements to the original ones would give us the graph shown below:
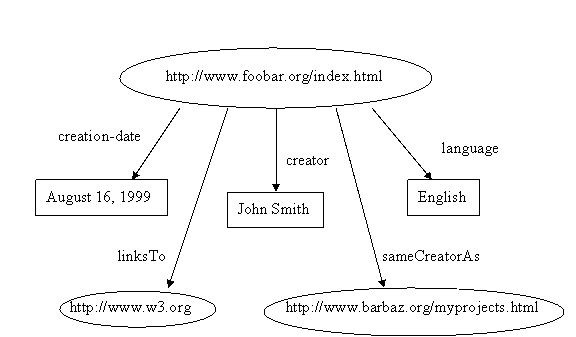
Figure 3
This graph illustrates another aspect of the way we represent RDF graphs
in drawings: nodes that represent URIs are shown as ellipses, while nodes
that represent strings are shown as boxes.
We first need to provide further detail about how RDF actually specifies the subjects, predicates, and objects of statements. So far, the identifiers we’ve used are:
We’ve recorded information about lots of things that don’t have URLs using files (both manual and automated) for many years, and the way we identify those things is by assigning them identifiers: values that we uniquely associate with the individual things. The identifiers we use to identify various kinds of things go by names like “Social Security Number”, “Part Number”, “license number”, “employee number”, “user-id”, etc. In some cases, these identifiers (such as Social Security Numbers) are assigned by an official authority of some kind. In other cases, these identifiers are generated by a private organization or individual. In some cases, these identifiers have a national or international scope within which they are unique (a Social Security Number has national scope), while in other cases they may only be unique within a very limited scope (my employee number is only unique among the numbers assigned by my specific employer). Nevertheless, these identifiers serve, if used properly, to identify the things we want to talk about.
As we’ve seen, the Web already provides one form of identifier, the Uniform Resource Locator (URL). A URL is a string that identifies a Web resource by representing its primary access mechanism (essentially, its network “location”). However, URLs are a subset of a more general and powerful concept, the Uniform Resource Identifier (URI). URIs (defined in [RFC2396]) are similar to URLs in that different persons or organizations can independently create them, and use them to identify things. However, unlike URLs, URIs are not limited to identifying things that have network locations, or use other computer access mechanisms. In fact, we can create a URI to refer to anything we want to talk about, including
Since the URI is such a general identification mechanism, capable of identifying anything, it should not be surprising that RDF uses URIs as its basic mechanism for identifying things. Specifically, uses URIs to identify both subjects and objects in RDF statements (the objects in some statements, such as age values or names, will still be identified by strings). In fact, RDF defines a resource as anything that is identifiable by a URI, and hence using URIs allows RDF to describe practically anything, and to state relationships between such things as well.
Now that we have URIs to identify resources, we can be more complete and precise about recording information. For example, instead of identifying the creator of the Web page in our original example by the string “John Smith”, we can assign him a URI, say (using a URI based on his employee number) http://www.foobar.org/staffid/85740 . The RDF statement stating this fact would then have the graph:
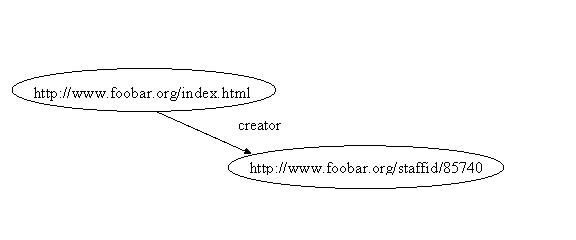
Figure 4
or, in the triples notation:
<http://www.foobar.org/index.html> creator <http://www.foobar.org/staffid/85740>
One advantage of using a URI to identify the creator of the page in this example is that we can be more precise in our identification. That is, the creator of the page isn’t the string “John Smith”, or any one of the thousands of people having “John Smith” as their name, but the particular John Smith associated with that URI (whoever created the URI defines the association). Moreover, since we have a URI for the creator of the page, it is a full-fledged resource, and we can record additional information about him, such as his name, and age, as in the graph
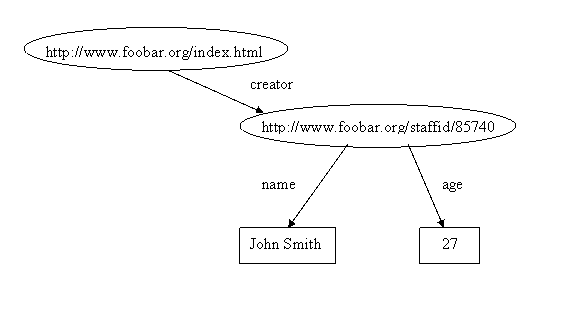
Figure 5
or the triples
<http://www.foobar.org/index.html>
creator <http://www.foobar.org/staffid/85740>
<http://www.foobar.org/staffid/85740> name
"John Smith"
<http://www.foobar.org/staffid/85740> age
"27"
We've just shown how RDF uses URIs as subjects and objects in its statements. However, in these latest examples, we’ve still oversimplified something. RDF also uses URIs as predicates in RDF statements. That is, rather than using strings such as “creator” or “name” to identify properties, RDF uses URIs..
Using URIs to identify properties is important for a number of reasons. First, it allows us to distinguish the properties we use from properties someone else may use that would otherwise be identified by the same text string. For instance, in our example, foobar.org uses “name” to mean someone's full name written out as a string (e.g., “John Smith”), but someone else may intend "name" to mean something different (e.g., the name of a variable in a piece of program text). A program encountering “name” as a property identifier on the Web wouldn’t necessarily be able to distinguish these uses. However, if foobar.org writes http://www.foobar.org/terms/name for its “name” property, and the other person writes http://geneology.org/terms/name for hers, we can keep straight the fact that there are distinct properties involved (even if a program can't automatically determine the distinct meanings). Another reason why it is important to use URIs to identify properties is that it allows us to treat RDF properties as resources themselves. Since properties are resources, we can record descriptive information about them (e.g., the English description of what foobar.org means by “name”), simply by adding additional RDF statements with the property's URI as the subject.
Using URIs as subjects, objects, and predicates in RDF statements allows us to begin to develop and use a shared vocabulary on the Web, reflecting (and creating) a shared understanding of the concepts we talk about. For example, now that we know to use URIs (where we can) to identify all the parts of an RDF statement, we can write the statement “the creator of http://www.foobar.org/index.html is John Smith“ as the triples
<http://www.foobar.org/index.html>
<http://purl.org/dc/elements/1.1/creator> <http://www.foobar.org/staffid/85740>
.
<http://www.foobar.org/staffid/85740> <http://www.foobar.org/terms/name>
"John Smith" .
The URI http://purl.org/dc/elements/1.1/creator for the “creator” property in the first triple is an unambiguous reference to the “creator” attribute in the Dublin Core metadata attribute set, a widely-used collection of attributes (properties) for describing information of all kinds. The writer of this triple is effectively saying that the relationship between the Web page (identified by http://www.foobar.org/index.html ) and the creator of the page (a distinct person, identified by http://www.foobar.org/staffid/85740 ) is exactly the concept defined by http://purl.org/dc/elements/1.1/creator . Moreover, anyone else, or any program, which understands http://purl.org/dc/elements/1.1/creator will know exactly what is meant by this relationship.
Incidentally, the triples above, using URIs in the subject, predicate, and (where appropriate) object positions (and with periods at the ends of the lines), are now in a formal RDF notation called Ntriples, which is defined for linearizing RDF graphs.
<http://www.foobar.org/staffid/85740> <http://www.foobar.org/terms/address> “1501 Grant Avenue, Bedford, Massachusetts 01730” .
However, suppose we wanted to record the various pieces of information about his address as separate street, city, state, and Zip code values? How do we do this using RDF?
In RDF, we can represent such structured information by considering the aggregate thing we want to talk about (like John Smith's address) as a separate resource, and then making separate statements about that new resource. So, in the RDF graph, in order to break up John Smith’s address into its component parts, we create a new node to represent the concept of John Smith’s address, and assign that concept a new URI to identify it, say http://www.foobar.org/addressid/85740 . We then write RDF statements (create additional arcs and nodes) with that node as the subject, to represent the additional information, producing the graph below:
@@Note: this figure needs to be redone, with <http://www.foobar.org/addressid/85740> in the current blank address node in the graph
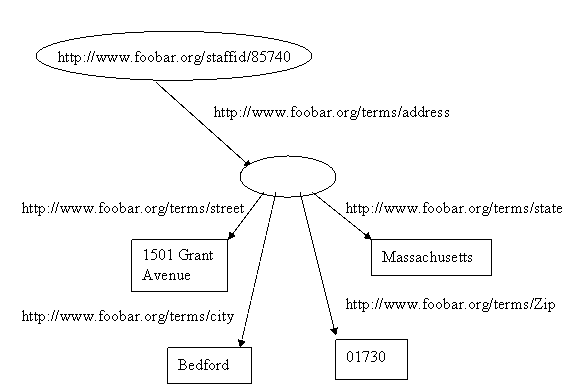
Figure 6
or the Ntriples:
<http://www.foobar.org/staffid/85740>
<http://www.foobar.org/terms/address> <http://www.foobar.org/addressid/85740>
.
<http://www.foobar.org/addressid/85740> <http://www.foobar.org/terms/street>
"1501 Grant Avenue" .
<http://www.foobar.org/addressid/85740> <http://www.foobar.org/terms/city>
"Bedford" .
<http://www.foobar.org/addressid/85740> <http://www.foobar.org/terms/state>
"Massachusetts" .
<http://www.foobar.org/addressid/85740> <http://www.foobar.org/terms/Zip>
"01730" .
In the drawing of the graph above, the new URI we assigned to identify "John Smith's address" really serves no purpose, since we could just as easily have drawn the graph
Figure 7
In this drawing, which is perfectly good RDF, we've used a node without a label to stand for the concept of "John Smith's address". This unlabeled node, or bNode (for blank node) functions perfectly well in the drawing without needing a URI. However, we do need some form of explicit identifier for that node in order to represent this graph in Ntriples. To see this, we can try to write the Ntriples corresponding to what is shown in Figure 7. What we would get would be something like:
<http://www.foobar.org/staffid/85740>
<http://www.foobar.org/terms/address> ??? .
???
<http://www.foobar.org/terms/street>
"1501 Grant Avenue" .
???
<http://www.foobar.org/terms/city>
"Bedford" .
???
<http://www.foobar.org/terms/state>
"Massachusetts" .
???
<http://www.foobar.org/terms/Zip>
"01730" .
where ??? stands for something that indicates the presence of the bNode. Since in a complex graph there might be more than one such bNode, we also need a way to differentiate between the various bNodes in the corresponding triples representation. To do this, the triples notation uses a concept of node identifiers (or nodeIDs) to identify bNodes. These are temporary identifiers distinct from URIs (and having their own syntax in Ntriples) that are used to indicate the presence of bNodes in the Ntriples representation. In this example, we might generate the node identifier _:johnaddress to refer to the bNode, in which case the resulting triples might be:
<http://www.foobar.org/staffid/85740>
<http://www.foobar.org/terms/address> _:johnaddress .
_:johnaddress
<http://www.foobar.org/terms/street>
"1501 Grant Avenue" .
_:johnaddress
<http://www.foobar.org/terms/city>
"Bedford" .
_:johnaddress
<http://www.foobar.org/terms/state>
"Massachusetts" .
_:johnaddress
<http://www.foobar.org/terms/Zip>
"01730" .
@@more about bNodes (?)
@@other subjects?
@@Primermodel12