Begin forwarded message:
From: Harry Halpin <hhalpin@w3.org>Subject: Re: Browser UI & privacy - a discussion with Ben LaurieDate: 5 October 2012 15:14:01 CESTTo: Henry Story <henry.story@bblfish.net>Cc: Hannes Tschofenig <hannes.tschofenig@gmx.net>, Melvin Carvalho <melvincarvalho@gmail.com>, public-identity@w3.org, "public-philoweb@w3.org" <public-philoweb@w3.org>, Ben Laurie <benl@google.com>
Thanks for bringing my thesis up.
However, I might add that the inability to support any degree of privacy/anonymity/multiple identities/unlink-ability due to a dogmatic idea over "linking" re URIs re server-to-server connections (See BrowserID for a nice solution to this) and lack of a user-interface is one of the reasons why I doubt WebID in its current form can succeed in the market. I think lots of people have expressed this problem and the WebID community has never modified their spec to enable these use-cases, and thus WebID is only appropriate to people who want to use RDF, don't mind the "self-signed cert" user interface, and want their public info on a web-page to link all their "identities" together. That is some group of people, I agree, but it's far from a magic bullet solution to identity.
I highly doubt bringing up philosophy will actually help here unless you can clarify what you mean re privacy, anonymity, multiple identities. There was some work by the IETF in this direction that seemed going in the right directions:
https://tools.ietf.org/html/draft-hansen-privacy-terminology-03
I also think this discussion should be confined to its proper mailing list. For example, if it simply becomes FOAF+SSL folks championing the wonders of RDF, then perhaps the discussion should remove other mailing lists than WebID. If its a philosophical discussion, then I'd keep it on philoweb. Or an identity discussion that's not dogmatic, keep on public-identity. This is basic etiquette.
cheers,
harry
On 10/04/2012 09:24 PM, Henry Story wrote:
[resent as the image was too big and so stripped from the mailinglist, making one part of the text incomprehensible ]
On 4 Oct 2012, at 17:10, Hannes Tschofenig <hannes.tschofenig@gmx.net> wrote:
Hi Melvin,
On Oct 4, 2012, at 4:49 PM, Melvin Carvalho wrote:
I think the aim is to have an identity system that is universal. The web is predicated on the principle that an identifier in one system (eg a browser) will be portable to any other system (eg a search engine) and vice versa. The same principle applied to identity would allow things to scale globally. This has, for example, the benefit of allowing users to take their data, or reputation footprint when them across the web. I think there is a focus on WebID because it is the only identity system to date (although yadis/openid 1.0 came close) that easily allows this. I think many would be happy to use another system if it was global like WebID, rather than another limited context silo.
I think there is a lot of confusion about the difference between identifier and identity. You also seem to confuse them.
Here is the difference:
$ Identifier: A data object that represents a specific identity of
a protocol entity or individual. See [RFC4949].
Example: a NAI is an identifier
$ Identity: Any subset of an individual's attributes that
identifies the individual within a given context. Individuals
usually have multiple identities for use in different contexts.
Example: the stuff you have at your Facebook account
This is a well know distinction in philosopohy. You can refer to things in two ways:- with names ( identifiers )- with existential variables ( anonymous names if you want ), and attaching a description to thatthing that identifies it uniquely among all other things
So for example Bertrand Russell considered that "The Present King of France" in "The Present King of France is Bald" wasnot acting like a proper name, but as an existential variable with a definite description. That is inmathematical logic he translated that phrase to:
∃x[PKoF(x) & ∀y[PKoF(y) → y=x] & B(x)]
Harry Halpin goes into this in this Philosophy of the Web Thesis
So yes we know this, and understand this very well. The Semantic Web is an outgrowth ofFregean logic, tied to the Web through URIs, and with some of the best logiciansin the world having worked on its design. This is our bread and butter.
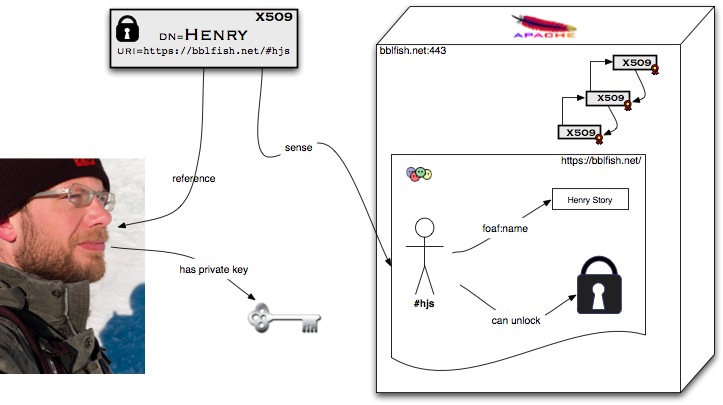
In fact in WebID we are using this to our advantage. What we do is we usea URI - a universal identifier - to identify a person, in such a way that it istied to a definite description as "the agent ID that knows the private key of publickey Key".[ image available at:
The text in the document named "http://bblfish.net/" says:
<#hjs> foaf:name "Henry Story";cert:key [ a cert:RsaPublicKey; cert:modulus ... ; cert:exponent ... ]
So in the above the Identifier is "http://bblfish.net/#hjs" which referes to <http://bblfish.net/#hjs>(me) which you can recognise as the knower of the private keypublished on the http://bblfish.net/ web page (in RDFa, in this case)
To illustrate the impact for protocols let me try to explain this with OpenID Connect.
OpenID Connect currently uses SWD (Simple Web Discovery) to use a number of identifiers to discover the identity provider, see http://openid.net/specs/openid-connect-discovery-1_0.html
The identifier will also have a role when the resource owner authenticates to the identity provider. The identifier may also be shared with the relying party for authorization decisions.
Then, there is the question of how you extract attributes from the identity provider and to make them available to the relying party.
In WebID that is easy for public info: you use HTTP GET.Otherwise you put protected info into protected resources, link to them from the WebID profile,and apply WebID recursively to the people requesting information about that resource. Ie: youprotect the resources containing information that needs protecting.
This makes it possible to describe people and their relations extremely richly,and it allows one to be very fine grained in who one allows access to information.
There, very few standards exist (this is the step that follows OAuth). The reason for the lack of standards is not that it isn't possible to standardize these protocols but there are just too many applications. A social network is different from a system that uploads data from a smart meter. Facebook, for example, uses their social graph and other services use their own proprietary "APIs" as well.
Yes, I know people keep saying its impossible, and then we have trouble showing them -
since the impossible cannot be seen.
Btw in WebID we use
The one well know api: HTTP.A semantic/logic model: RDF and mappings from syntax to that model - whichis based on Relations which I think Bertrand Russel showed to be pretty much all you needed.
Then it is a question of working together and developing vocabularies that metastabilise.(More on that in a future video).
This is the identity issue.
You are mixing all these topics together. This makes it quite difficult to figure out what currently deployed systems do not provide.
Ciao
Hannes
Social Web Architect
http://bblfish.net/
{kind=link}