SVG and HTML
SVG (Scalable vector graphics) is a powerful concept of describing
graphical elements and animations, based on XML. SVG was originally
designed as a presentation only framework (like scalable documents) and
slowly becoming more and more UI centric.
Things like user interactivity and animations are making SVG a good
candidate for integration in User Interface framework and WEB
Content Handler such as HTML in browsers,
utilizing its power of flexibility and scalability.
In many cases SVG is used as a stand-alone SVG content, but very often,
there is another markup language used as host of SVG. Example of such host
markup languages would be HTML, XUL, etc. To correctly integrate with (or
embed in) other markup languages, multiple things need to be considered.
This document addresses some of the issues that need to be taken into
consideration when creating a hybrid design. It also proposes a potential,
high-level solutions for some of those problems.
HTML/SVG Markup Integration Considerations
Interleaved Parsing of HTML/SVG
As the reader is probably already aware, HTML and SVG are both markup
languages. SVG follows the strict XML rules and HTML allows for a looser
syntax, like tags not been closed, etc.
To accommodate the complexity of integrating both, SGML & XML type
languages, SVG WG proposes a use of a cascaded parser. Cascading parser
allows recursive nested invocations between SGML and XML
Content Handler.
Since XML already defines how XML languages from different namespaces
interact with each-other, it is valid to have one XML language embedded in
another.
When embedding HTML inside SVG, the HTML markup must be well formed.
Example 1: SVG embedded in HTML
<head>
<title>HTML Body of SVG</title>
</head>
<body>
<form>
<svg width="480" height="640" id="svg1"
xmlns="http://www.w3.org/2000/svg" xml:space="preserve" version="1.2" baseProfile="tiny" >
<g fill-opacity="0.7" stroke="black" stroke-width="0.2" >
<circle fill="red" cx="100" cy="100" r="100"/>
</g>
</svg>
</form>
</body>
Eample 2: HTML embedded in SVG
<form>
<svg width="480" height="640" id="svg3" viewBox="-160 -120 480 640" stroke-miterlimit="2"
xmlns="http://www.w3.org/2000/svg" xml:space="preserve" version="1.2" baseProfile="tiny">
<g fill-opacity="0.7" stroke="black" stroke-width="0.2">
<table border="1">
<caption><em>A test table</em></caption>
<tr>
<th rowspan="2"></th><th colspan="2">Average</th>
<th rowspan="2">Red<br/>eyes</th>
</tr>
<tr>
<th>height</th><th>weight</th>
</tr>
<tr>
<th>Males</th><td>1.9</td><td>0.003</td><td>40%</td>
</tr>
<tr>
<th>Females</th><td>1.7</td><td>0.002</td><td>43%</td>
</tr>
</table>
<circle fill="green" cx="100" cy="100" r="100"/>
</g>
</svg>
</form>
Cascading Parser Structure
Cascading parser is combination of parsers, cascaded together to process
content of a different type – HTML and XML for example. The individual
parsers have their own rules, specific to the way the markup language is
structured. All of the individual parsers need to also follow common rules
of interactions with the other parsers.
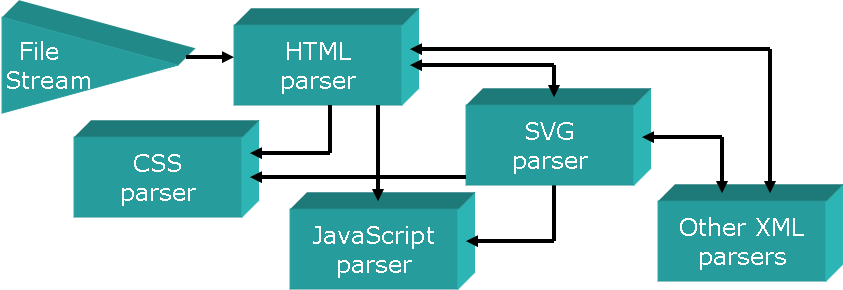
Content Handler
A Content Handler is a logical component,
which understands and processes particular content type.
Historically, the Content Handler are called
Content plug-ins. The interface is built for most plug-ins to only allow
for content inclusion by reference, i.e. no real content integration. For
example, displaying SVG from a plug-in in a WEB browser window, does not
make it integrated SVG Content Handler of
HTML. Only if elements of SVG can be interleaved with HTML content, then
it can be considered integrated. For example, it should be possible for an
SVG image and path elements to be displayed as elements of HTML table.
Another example is SVG text on path can be overplayed on top of HTML Image
object. From user visual perspective the content behaves as a single
markup language.
Content Processing
There are multiple steps a content processor needs to go through before a
markup stream becomes a visual representation of the input content. The
processing steps used are heavily based on the design of the
Content Handler. A legacy
Content Handler normally goes through more
steps than the contemporary SAX based parser processors. For example many
legacy Content Handler would tokenize the
stream and then start identifying and creating the elements representing
the tag elements in different steps.
Additionally, if the Content Handler
supports progressive parsing, it may process the content in a different
way to that of a non-progressive parser.
Regardless of the type of the parser the Content
Handler is using, the elements need to be identified from the
markup stream, created and displayed.
Content Processing Steps
These are the major content processing steps:
- Tokenizing
- Element Identification
- Element Creation
- DOM constructing and/or element addition
- Layout Re-flow
- Element rendering
Based on the implementation and the type of Content
Handler, some of the steps (listed above) can be combined in a
single operation and some of these can be broken down into more steps.
Note that Element Identification is
an important process in the cascading parsing schema.
Tokenizing
The purpose of the Tokenizing step is to break the stream down to tokens
that can be interpreted as elements and element attributes at the element
identification and construction stage.
HTML and XML have a very similar way of tokenizing. However, the tokeniser
must maintain information about token casing.
Element Identification
Element identification is a very important step in the cascading parser
schema.
Cascading parser maintains tables of:
-
Element tags – element constructor routines pairs (regular parsers also
have such table);
-
Reference to Content Handler, which
maintains "Element tag - Content Handler" pairs table;
- Namespace mapping table (for XML based parsers);
When a HTML parser encounters an unrecognized element during the element
identification step, it does the following:
-
Terminates the current element or attribute tag – For example it
terminates P, LI, TR, TH, etc. elements.
-
Makes a query of the Unknown Element tag to the
Content Handlers for a
Content Handler, which can handle the
unrecognized element.
-
If a suitable Content Handler is not
found, it obeys the HTML rules for undefined element(s).
-
If a Content Handler that can handle the
element is found, the HTML parser passes the control of the file or
token stream to the Content Handler.
Based on the implementation. The HTML parser may also need to pass
JS context and DOM branch reference to the identified
Content Handler.
-
The newly identified Content Provider, starts the processing of (SVG)
elements until it encounters unrecognized element error or a
namespace, which it can not handle. The SVG
Content Handler invokes the initial
Content Handler in an attempt to identify the unrecognized
element with another Content Handler.
-
If there is a Content Handler that can
handle the unrecognized element, the file or token stream is passed
the new Content Handler.
-
If there is no Content Handler found,
then the control of the stream is returned back to the initial
Content Handler of the stream. The
beginning of the element token that was not recognized is returned.
-
The HTML parser would need to continue processing the rest of the HTML
elements until it encounters another unrecognized element.
-
If the embedded Content Handler returns
with error and the content state is not recognized, the HTML parser
will thread the stream from this point on as malformed element and
should try to identify the first valid HTML element or a valid token
and recover the normal parsing flow.
In the example 1, the HTML parser is
going to find an element called SVG (or SVG:SVG) and going to query for a
content provider which can handle SVG element. If there is such a
provider, then the control of file or token stream is passed to the SVG
content provider along with optional JS and DOM branch references.
JavaScript Context Sharing
In cascaded parsing, when one Content
Handler passes the JavaScript context to next level below, it is
up to the new Content Handler to continue
using the existing parent's JavaScript context or create a new one.
Additionally, the parent Content Handler
may decide not to pass a valid JavaScript context to the embedded
Content Handler. In this case the embedded
Content Handler is forced to create a new
JavaScript context, if needed.
If an unified DOM3 interface is exposed from the embedded
Content Handler, it would be possible for
the parents JavaScript context to traverse the child nodes of the
embedded content. If this is not supported, the parent's JavaScript
content should be allowed to at least see the top-level content node
(SVG element for example and its attributes in the SVG content provider
case). Please note that attributes exposed in the last case can vary from
the standard SVG attributes. These attributes would be in relation to the
parent (from SVG also referred as User Agent SVG control attributes).
CSS Parsing Integration
Usually a separate parser than the host one is used for CSS rules.
A particular implementation may decide to pass the CSS processing rules
to the child Content Handler. However, it
is better to pass this information during re-flow and rendering phase of
the content processing.
For an SVG parser to correctly process the content, all the content
information, including namespace definition must be included in the
document. This would be OK, when sealing with SVG content which is
standalone as part of HTML frame or HTML object (this being the case of
example 1).
If the SVG content is embedded in HTML elements such as lists or
tables, then the content becomes very convoluted with the SVG namespace
information repeated over and over again (see
example 3).
Example 3
<form>
<table border="1" align="center">
<caption><em>A test table with SVG elements</em></caption>
<tr>
<svg id="svgRoot" version="1.2" baseProfile="tiny" viewBox="-160 -120 480 640"
width="480" height="640" stroke-miterlimit="2" zoomAndPan="enable" xml:space="preserve"
xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xe="http://www.w3.org/2001/xml-events">
<g fill-opacity="0.7" stroke="black" stroke-width="0.2">
<circle fill="red" cx="100" cy="100" r="100"/>
</g>
</svg>
</tr>
<tr>
<svg id="svgRoot" version="1.2" baseProfile="tiny" viewBox="-160 -120 480 640"
width="480" height="640" stroke-miterlimit="2" zoomAndPan="enable" xml:space="preserve"
xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xe="http://www.w3.org/2001/xml-events">
<g fill-opacity="0.7" stroke="black" stroke-width="0.2">
<circle fill="green" cx="100" cy="100" r="100"/>
</g>
</svg>
</tr>
<tr>
<svg id="svgRoot" version="1.2" baseProfile="tiny" viewBox="-160 -120 480 640"
width="480" height="640" stroke-miterlimit="2" zoomAndPan="enable" xml:space="preserve"
xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xe="http://www.w3.org/2001/xml-events">
<g fill-opacity="0.7" stroke="black" stroke-width="0.2">
<circle fill="blue" cx="100" cy="100" r="100"/>
</g>
</svg>
</tr>
</table>
</form>
If the SVG content is embedded in HTML elements such as lists or tables,
then the content becomes very convoluted with the SVG namespace
information repeated over and over again (see
example 3).
From example 3 it is obvious that the same
document definition information is repeated for every SVG element in
the HTML table. If the table had individual cells, the content would
look even more complex and bulky.
The SVG widget concept is addressing the issue of repeated SVG document
information by packing common document information at one place and
leaving in the embedded content the information only related to the SVG
elements or fragment (group of elements).
SVG Widget Structure
Example 4: SVG Widget Structure - svgDoc
<form>
<svgDoc id="svgRoot" version="1.2" baseProfile="tiny" viewBox="-160 -120 480 640"
width="480" height="640" stroke-miterlimit="2" zoomAndPan="enable" xml:space="preserve"
xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xe="http://www.w3.org/2001/xml-events">
<defs>
<style type="text/css">
<![CDATA[
circle { fill:red; stroke: blue; stroke-width:3 }
]]>
</style>
</defs>
</svgDoc>
...
</form>
Example 5: Reference SVG Widget (svgDoc) using svgWidget
<table border="1" align="center">
<caption> <em>A test table with SVG elements</em></caption>
<tr>
<svgWidget docId="myDoc1">
<g fill-opacity="0.7" stroke="black" stroke-width="0.2">
<circle fill="red" cx="100" cy="100" r="100"/>
</g>
</svgWidget>
</tr>
<tr>
<svgWidget docId="myDoc1">
<g fill-opacity="0.7" stroke="black" stroke-width="0.2">
<circle fill="gree" cx="100" cy="100" r="100"/>
</g>
</svgWidget>
</tr>
<tr>
<svgWidget docId="myDoc1">
<g fill-opacity="0.7" stroke="black" stroke-width="0.2">
<circle fill="blue" cx="100" cy="100" r="100"/>
</g>
</svgWidget>
</tr>
</table>
SVG Widget Advantage
- Makes the content lightweight
-
SVG fragments have a common place to control document attributes,
namespace definition, CSS
-
SVG widgets may have common or separate JavaScript context
-
Common JavaScript routines can be defined at the document level,
accessible from all the widgets, belonging to that particular document
-
Widgets size and position can be controlled from HTML layout
container (Tables, Lists, etc.)
High level view of the changes to HTML5
Summary of changes to HTML5 specification
Make tokeniser case-preserving
Remove hard coded table of case fixes for svg/mathml elements and
attributes (if still in the spec).
Merge the "U+0041 LATIN CAPITAL LETTER A through to U+005A
LATIN CAPITAL LETTER Z" and "U+0061 LATIN SMALL LETTER A
through to U+007A LATIN SMALL LETTER Z" cases, using the
definition for the latter, in:
- Tag open state: If the content model flag is set to the PCDATA state
- Close tag open state
Drop the "U+0041 LATIN CAPITAL LETTER A through to U+005A LATIN
CAPITAL LETTER Z" case in:
- Tag name state
- Before attribute name state
- Attribute name state
- After attribute name state
Change:
When the steps below require the UA to insert an HTML element for a
token, the UA must first create an element for the token in the HTML
namespace, and then append this node to the current node, and push it
onto the stack of open elements so that it is the new current node.
To:
When the steps below require the UA to insert an HTML element for a
token, the token and all attribute tokens it contains are first
normalized to lowercase [mapping A..Z to a..z]. If there are attribute
tokens with the same name it is a parse error, discard all attribute
tokens that are duplicates and the value that is associated with each
such token (if any), keep the first occurrence of an attribute token
whose name is duplicated. Then the UA must create an element for the
normalized token in the HTML namespace, and then append this node to
the current node, and push it onto the stack of open elements so that
it is the new current node.
Remove the paragraph:
When the user agent leaves the attribute name state (and before
emitting the tag token, if appropriate), the complete attribute's
name must be compared to the other attributes on the same token; if
there is already an attribute on the token with the exact same name,
then this is a parse error and the new attribute must be dropped,
along with the value that gets associated with it (if any).
Cases in the "in foreign content" insertion mode need to be
case-sensitive
Handle xml namespaces
Change the definition of "adjust foreign attributes"
Special parsing mode for SVG/MathML
Add the parse mode to "The in body insertion mode"
Sections of specification with changes
9.2.4 Tokenisation
- Tag open state
-
The behavior of this state depends on the
content model flag.
-
If the
content model flag is set to the RCDATA or CDATA states
-
Consume the
next input character. If it is a U+002F SOLIDUS (/) character,
switch to the
close tag open state. Otherwise, emit a U+003C LESS-THAN SIGN
character token and reconsume the current input character in the
data state.
-
If the
content model flag is set to the PCDATA state
-
Consume the next input character:
- U+0021 EXCLAMATION MARK (!)
-
Switch to the
markup declaration open state.
- U+002F SOLIDUS (/)
-
Switch to the
close tag open state.
-
U+0041 LATIN CAPITAL LETTER A through to U+005A LATIN CAPITAL LETTER Z
and U+0061 LATIN SMALL LETTER A through to U+007A LATIN SMALL LETTER Z
-
Create a new start tag token, set its tag name to the input character,
then switch to the
tag name state. (Don't emit the token yet; further details will
be filled in before it is emitted.)
- U+003E GREATER-THAN SIGN (>)
-
Parse error. Emit a U+003C LESS-THAN SIGN character token and a
U+003E GREATER-THAN SIGN character token. Switch to the
data state.
- U+003F QUESTION MARK (?)
-
Parse error. Switch to the
bogus comment state.
- Anything else
-
Parse error. Emit a U+003C LESS-THAN SIGN character token and
reconsume the current input character in the
data state.
- Close tag open state
-
If the
content model flag is set to the RCDATA or CDATA states but no
start tag token has ever been emitted by this instance of the
tokeniser (
fragment case), or, if the content model
flag is set to the RCDATA or CDATA states and the next few
characters do not match the tag name of the last start tag token
emitted (case insensitively), or if they do but they are not
immediately followed by one of the following characters:
- U+0009 CHARACTER TABULATION
- U+000A LINE FEED (LF)
- U+000C FORM FEED (FF)
- U+0020 SPACE
- U+003E GREATER-THAN SIGN (>)
- U+002F SOLIDUS (/)
- EOF
...then emit a U+003C LESS-THAN SIGN character token, a U+002F
SOLIDUS character token, and switch to the
data state to process the
next input character.
Otherwise, if the
content model flag is set to the PCDATA state, or if the next
few characters do match that tag name, consume the
next input character:
-
U+0041 LATIN CAPITAL LETTER A through to U+005A LATIN CAPITAL LETTER Z
and U+0061 LATIN SMALL LETTER A through to U+007A LATIN SMALL LETTER Z
-
Create a new end tag token, set its tag name to the input character,
then switch to the
tag name state. (Don't emit the token yet; further details will
be filled in before it is emitted.)
- U+003E GREATER-THAN SIGN (>)
-
Parse error. Switch to the
data state.
- EOF
-
Parse error. Emit a U+003C LESS-THAN SIGN
character token and a U+002F SOLIDUS character token. Reconsume the
EOF character in the
data state.
- Anything else
-
Parse error. Switch to the
bogus comment state.
- Tag name state
-
Consume the
next input character:
- U+0009 CHARACTER TABULATION
- U+000A LINE FEED (LF)
- U+000C FORM FEED (FF)
- U+0020 SPACE
-
Switch to the
before attribute name state.
- U+003E GREATER-THAN SIGN (>)
-
Emit the current tag token. Switch to the
datastate.
- EOF
-
Parse error. Emit the current tag token. Reconsume the EOF
character in the
data state.
- U+002F SOLIDUS (/)
-
Switch to the
self-closing start tag state.
- Anything else
-
Append the current input character to the current tag token's tag
name. Stay in the tag name state.
- Before attribute name state
-
Consume the
next input character:
- U+0009 CHARACTER TABULATION
- U+000A LINE FEED (LF)
- U+000C FORM FEED (FF)
- U+0020 SPACE
-
Stay in the
before attribute name state.
- U+003E GREATER-THAN SIGN (>)
-
Emit the current tag token. Switch to the
data state.
- U+002F SOLIDUS (/)
-
Switch to the
self-closing start tag state.
- U+0022 QUOTATION MARK (")
- U+0027 APOSTROPHE (')
- U+003D EQUALS SIGN (=)
-
Parse error. Treat it as per the "anything else" entry below.
- EOF
-
Parse error. Emit the current tag token. Reconsume the EOF
character in the
data state.
- Anything else
-
Start a new attribute in the current tag token. Set that attribute's
name to the current input character, and its value to the empty
string. Switch to the
attribute name state.
- Attribute name state
-
Consume the
next input character:
- U+0009 CHARACTER TABULATION
- U+000A LINE FEED (LF)
- U+000C FORM FEED (FF)
- U+0020 SPACE
-
Switch to the
after attribute name state.
- U+003D EQUALS SIGN (=)
-
Switch to the
before attribute value state.
- U+003E GREATER-THAN SIGN (>)
-
Emit the current tag token. Switch to the
data state.
- U+002F SOLIDUS (/)
-
Switch to the self-closing start tag
state.
- U+0022 QUOTATION MARK (")
- U+0027 APOSTROPHE (')
-
Parse error. Treat it as per the "anything else" entry below.
- EOF
-
Parse error. Emit the current tag token. Reconsume the EOF
character in the
data state.
- Anything else
-
Append the current input character to the current attribute's name.
Stay in the
attribute name state.
- After attribute name state
-
Consume the
next input character:
- U+0009 CHARACTER TABULATION
- U+000A LINE FEED (LF)
- U+000C FORM FEED (FF)
- U+0020 SPACE
-
Stay in the
after attribute name state.
- U+003D EQUALS SIGN (=)
-
Switch to the
before attribute value state.
- U+003E GREATER-THAN SIGN (>)
-
Emit the current tag token. Switch to the
data state.
- U+002F SOLIDUS (/)
-
Switch to the
self-closing start tag state.
- EOF
-
Parse error. Emit the current tag token. Reconsume the EOF
character in the
data state.
- Anything else
-
Start a new attribute in the current tag token. Set that attribute's
name to the current input character, and its value to the empty
string. Switch to the
attribute name state.
9.2.5.1. Creating and inserting elements
When the steps below require the UA to create an element for a token
in a particular namespace, the UA must create a node implementing
the interface appropriate for the element type corresponding to the tag
name of the token in the given namespace (as given in the specification
that defines that element, e.g. for an
a element in the
HTML namespace, this specification defines it to be the
HTMLAnchorElement interface), with the tag name being the
name of that element, with the node being in the given namespace, and
with the attributes on the node being those given in the given token.
The interface appropriate for an element in the
HTML namespace that is not defined in this specification is
HTMLElement. The interface appropriate for an element in
another namespace that is not defined by that namespace's specification
is Element.
When the steps below require the UA to insert an HTML
element for a token, the token and all attribute tokens it
contains are first normalized to lowercase [mapping A..Z to a..z].
If there are attribute tokens with the same name it is a parse error,
discard all attribute tokens that are duplicates and the value that is
associated with each such token (if any), keep the first occurrence of an
attribute token whose name is duplicated. The UA must then create an
element for the normalised token in the
HTML namespace. The newly created node must be appended to the
current node and push it onto the
stack of open elements so that it is the new
current node.
The steps below may also require that the UA insert an HTML element in
a particular place, in which case the UA must follow the same steps
except that it must insert or append the new node in the location
specified instead of appending it to the
current node. (This happens in particular during the parsing of
tables with invalid content.)
When the steps below require the UA to insert a
foreign element for a token, the UA must first
create an element for the token in the given namespace, and then
append this node to the
current node, and push it onto the
stack of open elements so that it is the new
current node. If the newly created element has an
xmlns attribute in the XMLNS namespace
whose value is not exactly the same as the element's namespace, that
is a
parse error.
When the steps below require the user agent to adjust
foreign attributes for a token, then for each attribute on the
token the following stemps must be applied:
-
If the attribute starts with
xml: and has one
or more characters following, let the attribute be a namespaced
attribute with the prefix xml, local name being
the characters after the colon, and the namespace being the XML
namespace, and abort these steps.
-
If the attribute starts with
xmlns: and has one
or more characters following, let the attribute be a namespaced
attribute with the prefix xmlns, local name
being the characters after the colon, and the namespace being the
XMLNS namespace, and abort these steps.
-
If the attribute is
xmlns, let the attribute a
namespaced attribute with no prefix, the local name
xmlns, and the namespace being the XMLNS namespace.
-
If the attribute starts with one or more characters other than the
colon that are followed by a colon that is followed by one or more
characters, and there is an attribute on the token or on an element
in the stack of open elements that is in the XMLNS namespace and has
the local name being the same as the characters before the colon on
the token, let the attribute be a namespaced attribute with the
prefix being the characters before the colon, the local name being
the characters after the colon, and the namespace being the value of
the matched XMLNS attribute. If there are multiple matching XMLNS
attributes, the one on the token takes precedence over the ones on
the stack [of open elements], and the bottommost node on the stack
takes precedence over the next-to-bottommost node on the stack and so
on.
9.2.5.10. The "
in body"
insertion mode
When the insertion mode is "
in body", tokens must be handled as follows:
...
-
A start tag whose case-sensitive tag name is "math" that has a
case-sensitive attribute "xmlns" with the value
"http://www.w3.org/Math/1998/MathML":
-
A start tag whose case-sensitive tag name is "svg" that has a
case-sensitive attribute "xmlns" with the value
"http://www.w3.org/2000/svg":
-
A start tag whose case-sensitive tag name is "<str>:math" that
has a case-sensitive attribute "xmlns:<str>" with the value
"http://www.w3.org/Math/1998/MathML":
-
A start tag whose case-sensitive tag name is "<str>:svg" that
has a case-sensitive attribute "xmlns:<str>" with the value
"http://www.w3.org/2000/svg":
-
Save the tokeniser content model flag to old-state.
Switch the tokeniser's content model flag to the CDATA state.
Create a new XML parser. Set the encoding to the character encoding
used by the HTML parser.
Feed the XML parser the string corresponding to the start tag of
the element along with all its attributes.
Let the XML parser parse and
insert the foreign element.
Then continue to feed character tokens to the XML parser until it:
- returns with a fatal error [XML10]
-
closes the current node (the element where XML parsing began),
with no errors
-
asks for another parser to handle an unknown tagname
If the XML parser returns a fatal error:
-
close all open elements on the
stack up to the
current node (the element where XML parsing began)
- Destroy the XML parser.
- Reset the tokeniser content model flag to the old-state.
- Reset the insertion mode appropriately.
If the XML parser returns with success, then destroy the XML
parser. Then reset the tokeniser content model flag to the
old-state and reset the insertion mode appropriately.
If the XML parser encounters a tagname which is unknown:
-
Save #state# on a stack: Push the tokeniser state, the insertion
mode and the XML parser.
-
Reset the tokeniser content model to the old-state. Reset the
insertion mode appropriately.
-
Hand over the token to the HTML5 parser.
-
When HTML5 parser encounters an tagname that is unknown hand the
token over to be handled by the parent parser (pop #state# ...).
9.2.5.19. The "
in foreign content" insertion mode
When the insertion mode is "
in foreign content", tokens must be handled as follows:
- A character token
-
Insert the token's character into the
current node.
- A comment token
-
Append a Comment node to the
current node with the data attribute set
to the data given in the comment token.
- A DOCTYPE token
-
Parse error. Ignore the token.
-
A start tag whose tag name is neither "mglyph" nor "malignmark", if
the
current node is an
mi element in the
MathML namespace.
-
A start tag whose tag name is neither "mglyph" nor "malignmark", if
the
current node is an
mo element in the
MathML namespace.
-
A start tag whose tag name is neither "mglyph" nor "malignmark", if
the
current node is an
mn element in the
MathML namespace.
-
A start tag whose tag name is neither "mglyph" nor "malignmark", if
the
current node is an
ms element in the
MathML namespace.
-
A start tag whose tag name is neither "mglyph" nor "malignmark", if
the
current node is an
mtext element in the
MathML namespace.
-
A start tag whose tag name is "svg", if the
current node is an
annotation-xml element
in the
MathML namespace.
-
A start tag, if the
current node is an element in the
HTML namespace.
- An end tag
-
Process the token
using the rules for the
secondary insertion mode.
The secondary insertion mode must be case-sensitve for these cases.
If, after doing so, the insertion mode is still "
in foreign content", but there is no element in scope that has
a namespace other than the
HTML namespace, switch the insertion mode to the
secondary insertion mode.