2004-01-09
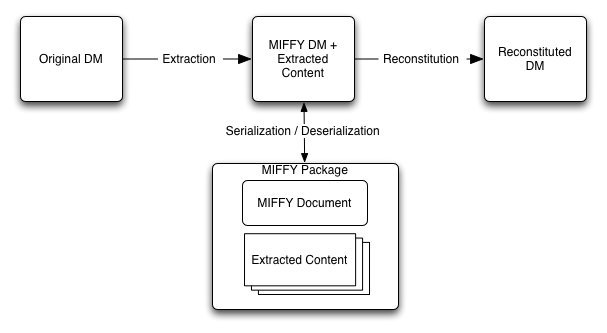
This specification defines the MIFFY convention, a means of serializing XML data models that have certain types of content more efficiently.
A MIFFY package is created by placing a serialization of the XML data model inside of an extensible packaging format (such as MIME/Multipart) and then re-encoding selected portions of its content alongside it, while marking their locations in the XML with a special element that links to the packaged data using URIs.
Optimization in MIFFY is limited to the content of those elements which contain characters that can be interpreted as base64-encoded data. Attributes and non-base64-compatible character data cannot be successfully optimized by MIFFY.
Because such content is transformed to binary data, and then re-encoded as canonical base64, care should be taken in selecting it. In particular, if the lexical form of the base64 data is important to preserve (e.g., a whitespace-sensitive signature algorithm is being used), it is important to ensure that such content is either canonical, or that it is not selected for optimization.
This specification uses terminology from the XML Query 1.0 and XPath 2.0 Data Model when discussing XML content and structure, because the Data Model allows content to be accessed both as characters and typed values. However, it is not necessary to use or implement an XQuery processor to create or process MIFFY Packages; the Data Model is used as a convenience in specification. It should also be noted that using this convention will not necessarily preserve Data Model-specific information (such as type information).
The remainder of this specification is organized in the following fashion:
Section Two of this specification describes the form of the MIFFY Package.
Section Three describes the MIFFY Data Model, which preserves the non-optimized content and structure of the original Data Model.
Section Four specifies MIFFY's processing model.
Section Five describes how MIFFY Documents are identified.
Section Six explores the security considerations of using the MIFFY convention.
Finally, Appendix A gives a mapping between Infosets and Data Models, so that MIFFY optimization can be used with Infoset-based formats.
The following terms are used in this specification;
[TBD]
The keywords "MUST", , "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119 [RFC 2119].
This specification uses a number of namespace prefixes throughout; they are listed below. Note that the choice of any namespace prefix is arbitrary and not semantically significant.
MIFFY is capable of using a variety of underlying packaging mechanisms. This section specifies how a particular packaging mechanism, MIME/Multipart, is used, but does not preclude the use of other packaging mechanisms with the MIFFY convention.
This section describes how MIME/Multipart packaging (as specified in [rfc2387]) is used with MIFFY.
The root MIME part is the root part of the package, and MUST be an XML 1.0 serialization [xml1.0] of the MIFFY Data Model, as defined below, and MUST be identified with the [ TBD ] media type.
Except for purposes of determining the root MIME part, as specified by [rfc2387], ordering of MIME parts MUST NOT be considered significant to MIFFY processing or to the construction of the MIFFY Data Model.
Part metadata is reflected in MIME header fields. Specifically, if the URI used in the value of a xbinc:Include element's href attribute has a 'cid' scheme, the corresponding MIME part's Content-ID header field MUST have a corresponding field-value. Otherwise, the MIME part's Content-Location header field MUST have a field-value identical to the URI in the value of the href attribute.
Furthermore, if a mime:content-type header is found (as described in "MIFFY Processing Model"), it SHOULD be reflected in the MIME Content-Type header's field-value.
A MIFFY Data Model MAY contain one or more xbinc:Include elements, whose semantic and content are defined below. Nodes other than those defined below MUST be ignored for the purposes of MIFFY processing.
The xbinc:Include element node accessor values are as follows:
[GUDGE: should not allow other children either]
The href attribute node has the following data model accessor values:
[ TBD ]
Unless otherwise stated, processing of MIFFY Packages MUST be semantically equivalent to performing the specified steps separately, and in the order given.
To create a MIFFY Package from an Original Data Model;
Other content-specific metadata MAY be reflected in the packaging metadata as appropriate.
If content cannot be successfully encoded into the MIFFY Data Model, implementations SHOULD behave as if that portion of the Original Data Model was not nominated for optimization.
To create a Reconstituted Data Model from a MIFFY Package;
[ TBD ]
[ TBD ]
This specification uses the XQuery 1.0 and XPath 2.0 Data Model to augment the information available in Infosets with typing information, which is used as the basis for optimization. This Appendix sets out in detail the correspondence between Infosets and data models, for purposes of implementation of this specification.
The [XML Query Data Model] provides a normative mapping from the Post Schema Validation Infoset to a data model. Except as specified here, that mapping is used to construct data models from infosets during serialization. The differences are as follows:
[NOAH: Should xdt:untypedAtomic be used for leaf nodes with only text content? Seems preferable to me, but for some reason the dm is looser.]
The [XML Query Data Model] provides a normative mapping from a Data Model to an Infoset. That mapping is used to construct an infoset during deserialization. Note that this mapping makes use only of dm:string and text node dm:children: in no case is the dm:type or dm:typed-value used to construct the Infoset. Thus, this mapping enforces the goal of this feature, which is to use type information as a means of optimization, without affecting application semantics.
Incorporate into illustration footnote regarding what happens when you start with an infoset vs. a data model