The
overall process of engaging a Web service was outlined in the
Introduction, and included the following steps: (1) the requester and
provider entities "become known to each other"; (2) the requester and
provider entities agree on the service description and semantics that
will govern the interaction between the requester and provider agents;
(3) the service description and semantics are embodied in the requester
and provider agents; and (4) the requester and provider agents exchange
messages. This section expands on Step 1.
If the requester entity does not already
know what provider agent it wishes to engage, then the requester entity
may need to "discover" a suitable candidate. Discovery is "the act of
locating a machine-processable description of a Web service that may
have been previously unknown and that meets certain functional
criteria." [WSAGLOSS]
(If the requester and provider entities are
already known to each other, then there is no need for discovery per se
-- they merely need to agree on the service description and semantics.
In that case, you can think of discovery as either being a null step or
a step that took place before the start of the described process.)
A discovery
service
is a service that facilitates the process of performing discovery. It
is a logical role, and could be performed by either the requester
agent, the provider agent or a third party agent.
Figure
9 ("Discovery Process") expands on Figure 1 to describe the process of
engaging a Web service when a discovery service is used.
[Figure
9: Discovery Process]
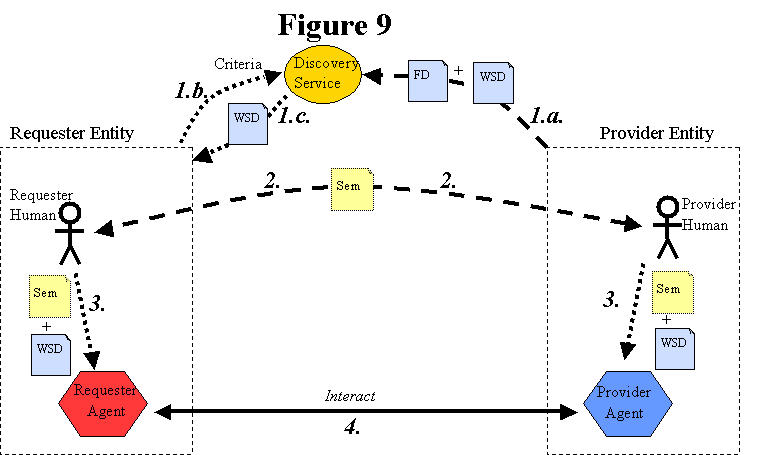
Service
engagement using a discovery service proceeds in roughly the following
steps.
-
The
requester and provider entities "become known to each other":
-
The
discovery service somehow obtains both the Web service description
("WSD" in Figure 9) and an associated functional description ("FD") of
the service.
The
functional description ("FD" in Figure 9) is a machine-processable
description of the functionality (or partial semantics) of the service
that the provider entity is offering. It could be as simple as a few
words or a URI, or it may be more complex, such as a TModel (in UDDI)
or a collection of RDF, DAML-S or OWL-S statements.
Because
functional descriptions need to be machine processable, written by many
provider entities and read by many requester entities, an appropriate
language for writing them should at least be:
This is an area that needs further standardization
work. One such effort is OWL-S.
The
WSA does not specify or care how the discovery service obtains the
service description or functional description. For example, if the
discovery service is implemented as a search engine (such as Google),
then it might crawl the Web, collecting service descriptions wherever
it finds them, with the provider entity having no knowledge of it. Or,
if the discovery service is implemented as a registry (such as UDDI),
then the provider entity may need to actively publish the service
description and functional description directly to the discovery
service.
-
The
requester entity (either a human or the requester agent) specifies
criteria to select a Web service description based on its associated
functional description and potentially other characteristics. At a
minimum, the criteria would be used to locate a service having the
desired functionality or semantics; however, it may be possible to
specify additional "non-functional" criteria related to the provider
agent, such as performance or reliability criteria, or criteria related
to the provider entity, such as the provider entity's vendor rating.
-
The
discovery service returns one or more Web service descriptions (or
references to them) that meet the specified criteria. If multiple
service descriptions are returned, the requester entity selects one,
perhaps using additional "non-functional" criteria.
-
The
requester and provider agree on the semantics ("Sem" in Figure 9) of
the desired interaction. Although this may commonly be achieved by the
provider entity defining the semantics and offering them on a
take-it-or-leave-it basis to the requester entity, it could be achieved
in other ways. For example, both parties may adopt certain standard
service semantics that are defined by some industry standards body. Or
in some circumstances the requester could define the semantics. The
important point is that the parties must agree on the semantics,
regardless of how that is achieved.
| Editorial note:
dbooth |
|
| We
need to fix an inconsistency in the document about our use of the word
"semantics". Sometimes we are referring to the semantics themselves,
whereas other times we are referring to a document that describes the
semantics. |
Step
2 also requires that the parties agree on the service description that
is to be used. However, since the requester entity obtained the Web
service description in Step 1.3, in effect the requester and provider
entities have already done so.
| Editorial note:
dbooth |
|
| We
need to fix a mismatch in granularity between the term "service
description" used here, and the term as used in the concepts and
relationships section (2.3.2.6). That section assumes that the "service
description" includes the semantics; this section (and WSDL) doesn't. |
-
The
service description and semantics are input to, or embodied in, both
the requester agent and the provider agent, as appropriate.
-
The
requester agent and provider agent exchange SOAP messages on behalf of
their owners.