1 Extensibility and Versioning
The primary motivation to allow instances of a language to be
extended is to decentralize the task of designing, maintaining, and
implementing extensions. It allows senders to extend the documents transmitted
without going through a centralized authority. To a great extent, the
Web rose dramatically in popularity because decentralized extensions
to HTML, HTTP and URIs were all possible. Each language provided
explict extensibility points and rules for understanding extensions
that enabled the decentralized evolution of the languages. The support
for the languages and their related rules are codified in a
continuously evolving set of software agents. This allows agents to
to continuously evolve, without a "big bang" upgrade.
It is almost unheard of for a single version of a language to be
deployed without requiring some kind of modification over time.
Knowing that a language will not be all things to all people, a
language designer can allow parties to extend instances of the
language or the language itself. Typically the language designer will
specify where extensions in the instance and extensions in the
language are allowed.
As documents, or messages, are exchanged between agents, they
are processed. Most agents are designed to discriminate between
valid and invalid inputs. In order to have any sort of
interoperability, a language must be defined or described in some
normative way so that the terms "invalid" and
"valid" have meaning.
There are a variety of tools that might be employed for this
purpose (DTDs, W3C XML Schema, RELAX NG, Schematron, etc.). These
tools might be augmented with normative prose documentation or even
some agent-specific validation logic. In many cases, the schema
language is the only validation logic that is available.
Whether you've deployed your agent on ten machines, or a
hundred, or a million, if you change a language in such a way that all
those appications will consider instances of the new language invalid,
you've introduced a versioning problem with real costs.
[Definition: Any change to a language
that permits some documents to be “valid” according to the language
before the change but not after or vice versa introduces a new
version of the language.].
Once a language is used outside of its development environment,
there will be some cost associated with changing it: software agents, user
expectations, and documentation may have to be updated to accommodate
the change. Once a language is used in multiple environments, any
changes made will introduce multiple versions of the language.
Extensibility is a property that enables software to evolve.
It is perhaps the biggest contributor to loose coupling in systems because
it enables the independent and potentially compatible evolution of
languages. [Definition: Languages
are defined to be extensible if instances of the language
can include terms from multiple vocabularies.]. An
extensible language is one with some syntax reserved for future use.
To extend a language is to define the syntax for some of the reserved
parts.
[Definition: A language
is an identifiable set of vocabulary terms that has defined
constraints.] For example, the elements and attributes of
XHTML 1.0 or the names of built-in functions in XPath 2.0. The
syntactic structure of the language is constrained by the use of DTDs,
XML Schema, other schema languages or narrative constraints expressed
in the relevant language specification. By language, we just mean the
set of elements and attributes, or components, used by a particular
agent.
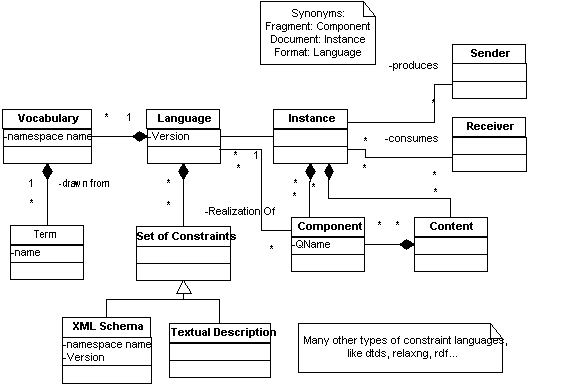
A language has one or more vocabularies. [Definition: A vocabulary is a set of
terms]. In general, the intended meaning of a vocabulary term
is scoped by the language in which the term is found. However, there
is some expectation that terms drawn from an XML Namespace have a
consistent meaning across all languages in which they are used.
An XML Namespace is a convenient container for collecting terms
that are intended to be used together within a language or across
languages. It provides a mechanism for creating globally unique
names.
[Definition: An instance is
a realization of a language]. Documents are instances of a
language. They must have a root element in XML.
[Definition:
Content is data
that is part of an instance of a language.] Content has one
or more components.
[Definition: A component
is a realization of a term in a language.] XML elements and
attributes are components. As a term has a name and the language has a
namespace name, each component has qualified name, that is the combination of
the namespace name and the name.
The interaction between agents and languages is described in terms
of senders and receivers. [Definition: A
sender is an agent that creates or produces an instance
and sends it to another agent for processing.]
[Definition: A receiver is an agent
that consumes an instance that it obtained from a sender.]
These terms and their relationships are shown below
[Definition: A
language is backwards compatible with another language if newer agents
can process all instances of the older language.] For example,
DocBook V4.1 is “backwards comaptible” with DocBook V4.0 because all
valid DocBook V4.0 documents are also valid DocBook V4.1 documents.
In the case of Web services, this means that new Web service
receivers, ones designed for the new version, will be able to process
all instances of the old language. A sender can send an old version of
a message to a receiver that understands the new version and still
have the message successfully processed.
[Definition: A
language is forwards compatible with another language if older agents
can process all instances of the newer language.] XSLT 2.0 is
“forward compatible” with XSLT 1.0 because all XSLT 2.0
stylesheets can be processed by XSLT 1.0 processors. Similarly, if all
documents that are valid with respect to version 5 of a particular
schema are also validate with respect to version 4, then version 5 is
forwards compatible with version 4.
In the case of Web services, this means that existing Web service
receivers, designed for a previous version of the language, will be
able to process all instances of the new language. This means that a
sender can send a newer version of a message to an existing receiver
and still have the message successfully processed.
In broad terms, backwards compatibility means that newer senders
can continue to use existing services, and forwards compatibility
means that existing senders can use newer services
The cost of changes that are not backward or forward compatible is
often very high. All the software that uses the language must be
updated to the newer version. The magnitude of that cost is directly
related to whether the system in question is open or closed.
[Definition: A closed
system is one in which all of the senders and receivers are
more-or-less tightly connected and under the control of a single
organization.] Closed systems can often provide integrity
constraints across the entire system. A traditional database is a good
example of a closed system: all of the database schemas are known at
once, all of the tables are known to conform to the appropriate
schema, and all of the elements in the each row are known to be valid
for the schema to which the table conforms.
From a versioning perspective, it might be practical in a closed
system to say that a new version of a particular language is being
introduced into the system at such and such a time and all of the data
that conforms to the previous version of the schema will be migrated
to the new schema.
[Definition: An open
system is one in which some senders and receivers are loosely
connected or are not controlled by the same organization. The internet
is a good example of an open system.]
1.1 Why Extend languages?
The primary motivation for allowing instances of a language to be
extended is to decentralize the task of designing, maintaining, and
implementing those extensions. It means that senders and receivers can
implement changes without seeking explicit approval from the language
owner. Consider the effort that the HTML Working Group put into
modularity of HTML. Without some decentralized process for extension,
every single variant of HTML would have to be called something else
or the HTML Working Group would have to agree to include
it in the next revision of HTML.
Good Practice
Allow Extensibility: Languages designers SHOULD
create extensible languages.
HTML 1.1, 2.0, and 3.2 are examples of extensible languages. They
allow for additional elements and attributes to be in document
instances that are not defined by the respective HTML DTD. HTTP is
another example of an extensible language as it allows new header
fields in HTTP messages.
Unfortunately, extensibility is not free. Providing hooks for
extensibility is another requirement that must be factored into the
costs of language design. Experience suggests that the long term
benefits outweigh the costs.
1.2 Identifying and Controlling Languages
Some changes make a language completely incompatible with previous
versions. Changes can also be backwards and forwards compatible.
Designing languages to support compatible changes reduces the cost of
those changes.
In an open system, it's simply not practical to handle language
evolution with universal, simultaneous, atomic upgrades to all of the
software components. Existing senders and recievers outside the
immediate control of the organization that's publishing a changed
language will continue to use the previous version for some (possibly
long) period of time.
Finally, it's important to remember that systems evolve over time
and have different requirements at different stages in their life
cycle. During development, when the first version of a language is
under active development, it may be valuable to persue a much more
aggressive, draconian versioning strategy. After a system is in
production and there is an expectation of stability in the language,
it may be necessary to proceed with more caution. Being prepared to
move forward in a backwards and forwards compatible manner is the
strongest argument for worrying about versioning at the very beginning
of a project.
Controlling the evolution of a language relies on two assumptions:
The agent must understand the semantics of every valid message
that it receives. We must therefore define the semantics of messages
that contain new elements or attributes.
We assume that each service rejects invalid messages. Therefore, it
must be possible for our language to evolve without changing the
schema that we've defined for it. New versions of a service might be
deployed with newer schemas, but we want these new services to be able
to communicate with the already deployed senders and receivers that
will continue to use the old schemas. That is why forwards compatible language
changes have to be possible without changing the schema.
In order for a schema to be extensible in the way described above,
to allow new elements or attributes to be added without changing the
schema, the schema must allow extension in any namespace. This brings
us to the next rule for enabling a must ignore versioning strategy in
XML languages:
Good Practice
Any Namespace: Every language SHOULD provide for
extension in any namespace.
If one extreme position is not to allow any extensions at all, then
the opposite extreme is to allow extension everywhere: in every
content model and on every element. In practice, allowing extensions
everywhere may not be cost effective. For many languages, it may be
possible to identify the smallest units that can effectively be
extended and simply allow extension at those points and above. Bear in
mind however that the cost of failing to allow extension where it is
eventually needed may be much higher than the cost of allowing it
in more places than obviously necessary today.
It usually makes sense to allow extension in attributes as well.
Good Practice
Full Extensibility: All XML Elements that can allow attributes, ie ComplexTypes in XML Schema, SHOULD
allow any attributes and any elements in their content models.
The corollary of extensibility in any namespace, including the language's namespace, is that a namespace does not identify a single version of a language or set of names. A namespace identifies a compatible set of names.
Good Practice
Namespace identifies compatible names: The namespace name SHOULD identify names that are compatible within the same namespace name.
Given that a namespace name is not for a single version of a
language or set of names, it may be useful to identify the particular
version. An example would be specifying in a policy statement the
exact language supported by a software agent. This use of version
identification could be considered each compatible "minor" version,
with the namespace name identifying the incompatible versions.
Good Practice
Identify specific version with version attribute:
The specific version of a set of names within a given namespace MAY be
identified with a version attribute to differentiate between the
compatible versions
1.3 Understanding Extensions
The key value of providing extensibility as described above is that
existing XML documents may be extended without having to change
existing agents. In order to allow existing agents to process extensions, the extension model must also specify agent behaviour in the presence of extensions. For languages that are intended to be
extensible, specifications SHOULD provide a clear processing model for
extensions.
Good Practice
Provide Processing Model: Languages SHOULD
provide a processing model for dealing with extensions.
Failing to provide a processing means that extensions, including compatible changes, are typically predictably usable, as the receiver will not behave predictably.
As an existing agent cannot know the intended semantics of a component that its never seen before there are realistically two options: ignore that component or generate an error. Both these models are at least predictable. However, the error processing model does not allow for extensibility or compatible changes. We propose, therefore, that agents
"must ignore" elements and attributes they do not recognize.
For many agents, including most Web services, the most
practical rule is: must ignore.
Good Practice
Must Ignore: Receivers MUST ignore any XML
attributes or elements that they do not
recognize in a valid XML document.
This rule does not require that the elements be physically removed;
only ignored for most processing purposes. It would be reasonable, for example,
if a logging agent included unrecognized elements in its log. There are cases where the elements should not be physically removed. An example is an agent that forwards the content to another receiver should preserve the unknown content.
HTTP 1.1 is an example of a language that specifies that receivers should ignore any headers that it doesn't understand. RFC 2616 says "Unrecognized header fields SHOULD be ignored by the recipient and MUST be forwarded by transparent proxies."
agents must deal carefully with the ignored elements,
especially if any of them are counted or if the agent makes use
of information about their position.
There are two broad types of languages relating to dealing with extensions. These two types are presentation or document and data oriented agents. For data oriented agents, such as Web services, the rule is:
Good Practice
Must Ignore Component and descendents: The Must Ignore rule applies to unrecognized elements and their descendents.
The purpose of ignoring the descendents is that the descendent components are usually semantically coupled with the ancestor, and the meaning of the descendents cannot be inferred without the ancestor. For example, an address component that is understood but is a child of an unknown purchase order component has an unknown semantic on it's own.
Document oriented languages need a different rule as the agent will still want to present the content of an unknown element. The rule for document oriented agents is:
Good Practice
Must Ignore Component only: The Must Ignore rule applies only to unrecognized elements
This retains the descendents of the ignored container element, such as for display purposes.
An example of the Must Ignore Component only is HTML 1.1, 2.0 and 3.2. They specify that any unknown start tags or end tags are mapped to nothing during tokenization.
In order to accomodate big bang changes when they are needed, the
must ignore rule is not expected to apply to the root element. If the
document root is unrecognized, the entire message must be
rejected.
1.4 Versioning Languages
The principles above distribute the notion of versioning
into the components that constitute messages. Changes that are compatible with the extension
mechanism do not require a namespace change.
Good Practice
Re-use Namespace Names and Element Names: If
a backwards or forwards compatible change is made to an element
definition by the owner of the element's namespace, then the old
namespace name and element names SHOULD be used in conjunction with
the extensibility model.
As indicated above, some changes simply introduce incompatibility.
There are a few distinct types of backwards incompatible change:
A required information item is added.
The semantics of an existing information item are changed.
The maximum number of allowable items is reduced. This change does
not guarantee incompatibility. Instance documents where the maximum
number allowable is still greater than or equal to the number of
occurrences will still be vaild. If the maximum number of allowable
items is reduced below the minimum number of a previous version, then
incompatibility is guaranteed.
1.5 Namespace content changes
Only the owner of a namespace can change (ie. version) the
meaning of elements and attributes in that namespace.
Constraint
Only Namespace Owners Change Namespace: The namespace name owner is the only entity that is allowed to change the meaning of names in a namespace.
One interesting example of this is the use of the XML Schema data type namespace name. The XML Query Working Group received permission from the XML Schema working group and the domain owner (W3C) to augment the XML Schema data type namespace without changing the namespace name. In this case, the namespace name owner changed the meaning of its names by granting permission to another group.
There is a school of thought that says that every extension should
be placed in a separate namespace; that after publication, no new
names should be added to a namespace. If you hold
that point of view then you may not feel that an extensibility element
is necessary or desirable. In the previous example, that would mean that XML Query would require a new version of the XML Schema in order to use a single XML Schema data type namespace.
Another school of thought says that the maintainers of the language
have a right to add new names to a namespace as they see fit. There are certain advantages
associated with adding new names in the same namespace.
It reduces the number of namespaces needed to describe
instances of the document. There are significant convenience
advantages to using defaulted namespaces for document creation and
manipulation.
It provides a clear separation between extensions by the
language designers and extensions by third parties.
There may be additional benefits in code generation and reuse
if single namespace or a small set of namespaces can completely describe
the language.
A namespace name owner will use the lifecycle of the namespace as one of the factors in determining whether to revise the namespace or not. Typically, the changes during development are not compatible changes. The author of namespaces that are under development will typically follow a "big bang" approach. This helps reduce the number of potentially buggy or immature implementations that are deployed. A W3C specification is a good illustrative example. It will probably change namespace names for each working draft. The Candidate Recommendation, Proposed Recommendation and Recommendation namespaces names should only be changed if compatibility is not achieved.