- From: <Patrick.Stickler@nokia.com>
- Date: Mon, 17 Dec 2001 03:19:45 +0200
- To: pfps@research.bell-labs.com
- Cc: www-rdf-interest@w3.org
- Message-ID: <A03E60B17132A84F9B4BB5EEDE57957B160B43@trebe006.NOE.Nokia.com>
> How can RDF exist without some sort of API?
This is like asking how XML can exist without an API. Of
course, it can't, per se. But that API need not be a native
component of the representation. Thus, we have SAX, DOM, etc.
as APIs for XML and we should, I fully agree, have a standardized
API for RDF -- but it need not be defined by RDF.
> RDF has to be able to pass data to applications
> somehow? How is this to be done?
No. RDF does not "pass" anything to any application. It is
akin to XML. It is only the representation of knowledge, not
any specific procedures or functions for the manipulation
or interpretation of that knowledge.
I agree that a standardized RDF API is sorely needed, but
this is a layer above RDF, not part of RDF itself (taking
the very strict meaning of "RDF" referring to the three
components (a) graph model, (b) serialization, and (c) core
vocabulary/ontology.
The API is not part of that strict, core definition of RDF.
And the key point is that the API should not define or dictate
how data typing is expressed in the graph, though it may
provide useful abstractions or higher level views of data
typing knowledge.
> > That's out of
> > scope insofar as how we are going to capture that data typing
> > knowledge in the RDF graph itself, in a way that is independent of
> > any data typing scheme or any particular representation used by
> > any given platform.
> >
> > I will reiterate, RDF should not use XML Schema data types natively
> > in the graph.
>
> I just don't understand this approach. If RDF is going to
> have datatypes
> at all, then it has to have some understanding of the
> datatypes, otherwise
> entailment cannot be performed.
This is perhaps the point of disconnect. RDF should not (and I expect
will not) *have* data types. RDF will provide consistent, explicit,
and standardized mechanisms for associating data types with literals
(or any resource). It is then up to the application to infer and
execute all mappings from lexical forms to values, and that execution
will differ from platform to platform as the internal canonical
representations for values are specific to platform.
RDF will provide the knowledge required to test entailment, but does
not itself "perform" such entailment -- i.e. an RDF parser or RDFS
validator is not going to say anything about that, no more so than
whether two URIs actually denote the same "thing".
> A formalism that allows various datatyping schemes to be incorporated
> has to solve all the problems that a formalism that just
> incorporates a particular datatyping scheme, and more.
Again, RDF is not "incorporating" multiple data typing schemes, it is
supporting arbitrary data typing schemes by providing a generic method
of associating the identity of specific data types to resources. Those
are two very different things. Simple typed values are not explicit in
the RDF graph, only the knowledge which uniquely identifies those
values. Because RDF is a platform neutral representation that must work
with a unrestricted range of languages, platforms, etc. you cannot
have any explicit, internalized, canonical representation for values in
the RDF graph.
> In particular, how are you going to determine whether
>
> age rdfs:range xsd:integer .
> John age "10" .
>
> entails
>
> John age "010" .
Just as any application which is going to utilize knowledge expressed
in RDF must have some basic "understanding" of the semantics attributed
to the ontologies used, likewise any application which is going to
manipulate typed literals expressed in RDF must have some basic
"understanding" of the data types associated with those literals.
So, an application which knows about the data type xsd:integer will
know how to map those two lexical forms to values in its own internal
canonoical value space corresponding to the abstract value space for
xsd:integer and once they are mapped to internal values, it can compare
them.
> > > In this case RDF does not have datatypes.
> >
> > BINGO! RDF itself should not *have* datatypes. It should provide
> > a generic mechanism for allowing data types to be associated with
> > literals (or really, any resource).
>
> But then you haven't done anything. If you truely believe
> this, then why
> are you arguing for PDU?
PDU does not add data types to RDF. PDU is (a) a view of how data typing
can be defined in terms of a pairing of lexical form and data type
identity which uniquely and unambigously identifies a specific value
in the value space of that data type and (b) a set of idioms which all
synonomously provide for defining such pairings in the RDF graph, each
with benefits in particular areas: P providing for local definition,
D(AML) providing for local explicit definition, and U providing for
local definition which facilitates in maximal graph compression.
In fact, the S proposal can be interpreted as a fourth idiom which
defines these pairings by means of property constructs.
> > The PDU proposal accomplishes this fully, and is also the way folks
> > are doing data typing in RDF now. And it works.
>
> I dispute all three of these claims. First, I have recently
> sent you a
> message concerning difficulties in PDU.
I've not yet gotten to that, but will reply separately.
> Second, PDU places
> restrictions on
> data typing that are not enforced by current RDF and, I
> expect, are not
> followed by many uses of data typing in RDF.
What restrictions?
> Third, PDU does
> not provide a
> full account of what datatypes mean in RDF.
While the documentation may at the moment be a bit sparse, and
thus, you have a (temporarily) valid criticism, the conceptual
foundation of PDU, namely the view of data typing based on pairings
of lexical form and data type which infer the mapping of lexical
form to value, is compatible with (and I would venture to say is)
the general concensus of what data typing "means" in RDF, and
will have (and likely already has) full treatment in the MT.
Pat and others are of course free to correct me here if I'm wrong.
The latest Data Typing draft produced by Sergey is analogous to
the PDU view, though it does not mention (yet ;-) PDU pairings.
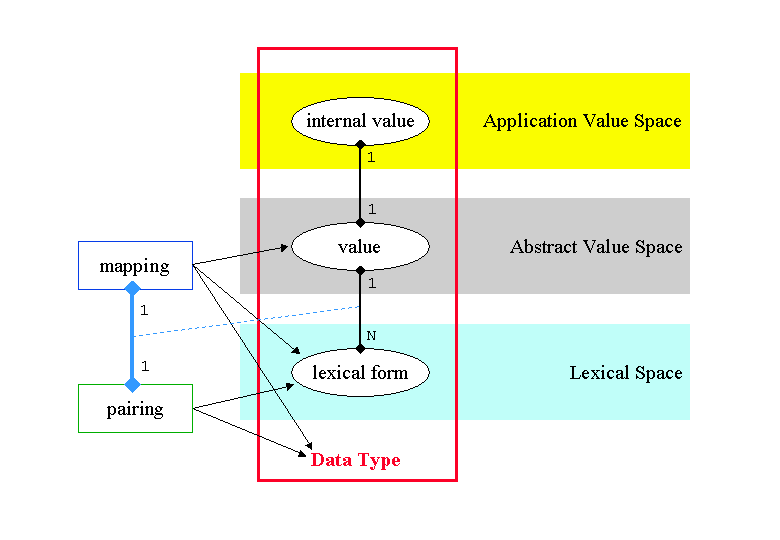
The attached graphic should help to illustrate these relations.
I understand that you would like the RDF data typing solution
to address all three levels explicitly (including the Application
Value Space) and it's my assertion that this would be contrary
to the generic, application neutral purpose of RDF.
> > > Because
> > > RDF does not
> > > understand the conventions no RDF document should mention them.
> >
> > I don't follow your argument here.
>
> If something is not defined by RDF then no RDF document
> should talk about
> that thing. (For example, if datatypes are not defined in
> RDF then no RDF
> document should be talking about datatyping.)
If you are proposing that RDF should add mechanisms to actually
define (a) the canonical representation for all values for all
data types and (b) the algorithms needed to define the actual
mappings from lexical space to value space, then RDF is quickly
going to become terribly limited and impractical. XML doesn't
define the semantics of XHTML or SOAP, why should RDF define
the semantics of a particular data typing scheme?
> And, by the way, XML did make changes to <p>. Just try to pass an
> old-style HTML document through an XML parser and see how
> many errors you
> get.
Ummm, no. The mis-usage of <p> as an empty element in HTML was
both bad SGML and bad XML. XML did not change anything. Browsers
are still free to interpret non-well-formed XML just as they were
free to interpret non-well-formed SGML, but that doesn't mean
such encodings are correct.
> If "2+5" denotes '7' then RDF needs to know it so that it can
> determine
> that
>
> John age "2+5" .
>
> entails
>
> John age "7" .
Well, if we are presuming the typing
age rdfs:range xsd:integer .
then "2+7" is not a legal lexical form for that data type. Though
if you replaced "2+7" in your example with the earlier "010", then
I do understand what you are trying to accomplish, but I also
still feel that the graph itself is the wrong level to do this.
Just as you need a higher level of processing logic to validate
RDFS constraints, catch and deal with contradictions, handle
statements of equivalence or subclassing, etc. you also need that
higher level of dealing with entailment of typed data literal
values. What is important/crucial is that you have all the knowledge
you need to do that expressed in the graph. The mechanisms, vocabulary,
and representations employed in the graph itself should be application
neutral, generic, flexible, and as future proof as possible, and adding
native data types with explicit internalized canonical representations
of typed values in the graph defeats that purpose, and IMO would
substantially reduce the utility of RDF.
Regards,
Patrick
--
Patrick Stickler Phone: +358 50 483 9453
Senior Research Scientist Fax: +358 7180 35409
Nokia Research Center Email: patrick.stickler@nokia.com
Attachments
- application/octet-stream attachment: data-types.png
{kind=link}
Received on Sunday, 16 December 2001 20:19:58 UTC