- From: Richard Ishida <ishida@w3.org>
- Date: Tue, 22 Jan 2008 18:49:05 -0000
- To: "'I18N'" <www-international@w3.org>
- Message-ID: <00ef01c85d27$772bdc50$658394f0$@org>
I reviewed sections 1-3.
[1] editorial
Section 3(.0) says " To avoid ambiguity with the computer use of the term character, this is called a user-perceived character or a grapheme cluster.".
Section 1 para 1 replaces 'grapheme clusters ("user-perceived characters")' with 'user-perceived characters', but should probably say 'grapheme clusters (also known as user-perceived characters)'.
S1 para 4 replaces 'grapheme clusters (what end users usually think of as characters)' with just 'characters'. This is incorrect.
S2 para1 deletes 'grapheme clusters' and leaves 'user-perceived characters'.
This is very inconsistent.
I would prefer to see just one term used, and I would prefer that to be 'grapheme cluster' to help associate it more clearly in the reader's mind with terms like 'default grapheme cluster'. Indeed much of the text does use that term already. That should be explained in terms of user-perceived characters at the beginning of sections 1 and 3 with some kind of highlighting to help people find the definition, although it would be even more useful to additionally include a short glossary in the document and link the first use of the term in each section to the glossary.
[2] editorial?
The document calls out Thai and Lao in addition to Chinese and Japanese, due to the fact that they don't use spaces between words. Khmer and Myanmar should be added to the list, or it should be made clear that this is a non-exhaustive list.
[3] editorial
S3 para starting "Grapheme clusters are important for..."
I would like to see this para expanded to provide a more complete list of potential applications for the grapheme cluster. Eg. mouse selection, cursor movement and backspace (and presumably delete) are mentioned later.
Note that applications we have come across recently include segmentation for vertical text and identification of boundaries for first-letter styling. Segmentation of indic and south-east asian scripts for these applications is done on a syllabic basis. (See examples at http://www.flickr.com/photos/ishida/2212584968/ and http://www.w3.org/International/notes/firstletter.html )
[4] editorial
" Extended default grapheme clusters should be used in implementations in preference to default grapheme clusters, because it provides better results for Indic scripts such as Tamil."
This should come much earlier and be easier to find. I would suggest that very near the beginning of section three the document states that it defines two types of grapheme cluster, and that the extended one is the preferred.
There also needs to be a section heading for the definition of XDGCs. The current definition is difficult to find because it is just a small adjunct to the section about default grapheme clusters.
[4a] editorial? Substantive?
'Indic scripts such as Tamil' doesn't sound right. I was expecting to read something like 'Indic scripts, such as the Tamil we saw earlier' or 'most Indic scripts', but maybe I'm assuming too much and it says that because it only helps simpler Indic scripts like Tamil as opposed to the majority of Indic scripts that use conjuncts liberally? If this is the case, a. we need to be clearer about the scope of the benefits to be had from XDGCs, and b. I think we are definitely setting our sights too low.
[5] editorial
Talking about Hangul characters "One way to think of this is as a sequence of characters that form a "stack"." Some jamos stand side by side rather than stacking. Surely the point is that this constitutes a Korean syllable.
[6] substantive
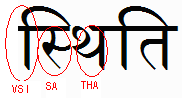
I don't think extending default grapheme clusters to just incorporate spacing marks goes far enough to actually "providing better results for Indic scripts". It is very common to have a sequence such as consonant+virama+consonant+vowel_sign, eg.
0938: स DEVANAGARI LETTER SA
094D: ् DEVANAGARI SIGN VIRAMA
0925: थ DEVANAGARI LETTER THA
093F: ि DEVANAGARI VOWEL SIGN I
See attached image (sthiti.gif).
Without tailoring, the current rules would result in text wrapping the THA to the next line, or attempting to highlight only part of the conjunct. The basic unit for grapheme clusters for indic and south-east asian scripts is surely the syllable, and just addressing spacing marks will still leave you short of a useful solution.
It seems, also, without having examined this in detail, that it may be fairly easy to state rules so that something like
base + vowel_killer + base + combining_vowel(s) + other_combining_mark(s)
would constitute a grapheme cluster by declaring that any base character after a vowel_killer is incorporated into the grapheme cluster along with any combining marks that follow it.
[7] editorial/substantive
"Khmer subjoined consonants such as consonant sign coeng ka: 17D2 ( ្ ) KHMER SIGN COENG + 1780 ( ក ) KHMER LETTER KA "
This is described as a type of grapheme cluster, which makes it sound like one of the things we are defining here. There is nothing to indicate the contrary in the text near this bulleted list.
And yet this is not a grapheme cluster as per the definitions given later, since the subscript letter is a normal consonant character in the text stream.
[8] substantive
In the case of Khmer, the subscript consonants are viewed as distinct letters by Cambodians, so I am assuming that it would make sense to delete them separately from the 'base' character above them. On the other hand, I'm not sure it would make sense to highlight them separately from the rest of the syllable, especially since there could be some discontinuity between the subscript consonant and the following vowel sign. Eg. ក្លី
1780: ក KHMER LETTER KA
17D2: ្ KHMER SIGN COENG
179B: ល KHMER LETTER LO
17B8: ី KHMER VOWEL SIGN II
Note, also, that vowels can appear to the left or on both sides of the stack produced by coeng combinations, and you wouldn't want to wrap inside the sequence of base characters, vowels and other combining marks any more than you would for the devanagari above.
So I'm wondering whether we can expect to define a single type of grapheme cluster that is appropriate for both of these operations. Perhaps we can define different behaviours for different operations.
I think that to fall back to just adding spacing combining marks to default grapheme clusters and expecting implementations to take care of the rest is a cop out that leaves us with something that is of little use in (a very large part of) the real world.
(Note that I also think that abandoning extended default grapheme clusters and going back to the current definition of default grapheme cluster is a step further backwards.)
[9] editorial
" Additional cases need to be added for complete, whereby any string of text "
Syntax error!
[10] editorial
"Note: Default grapheme clusters have been referred to as"
This could point to a problem with terminology. Is 'default grapheme clusters' meant to include default grapheme clusters of the extended and existing types? I would have thought so, but the meaning of the text is not clear. You'd need to say 'default grapheme clusters and extended default grapheme clusters' here to be clear (and elsewhere in the text, eg. 4 paras later). We could rename the current 'default grapheme cluster' to 'minimal default grapheme cluster' and define 'default grapheme cluster' to refer to both the minimal and extended varieties, or you could simply use 'grapheme cluster' when you want to be non-specific.
============
Richard Ishida
Internationalization Lead
W3C (World Wide Web Consortium)
http://www.w3.org/International/
http://rishida.net/blog/
http://rishida.net/
Attachments
- image/gif attachment: sthiti.gif
Received on Tuesday, 22 January 2008 18:45:36 UTC