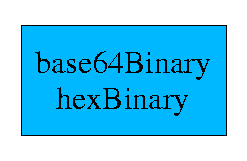XML Schema Datatypes in RDF
Author: Jeremy Carroll
26 November 2002
Contents
Status
This is the author's opinion intended as input
to the W3C RDF Core and XML Schema Working Groups.
It is proposed as input
to either the RDF Concepts and Abstract Syntax WD [RDF Concepts]
or a joint Note from the RDF Core and XML Schema Working Groups.
In [RDF Concepts], the central
aspects of datatyping in RDF are outlined.
One of those is that actual datatypes are not
provided as part of RDF, but the use of XML
Schema Datatypes is encouraged.
The [XML Schema Datatypes], while presenting
a reusable datatype framework, has XML developers as
its primary audience.
Within the RDF abstract syntax, equality is a key concept.
This is to ensure that RDF is adequately formalizable, to be
the foundations of the Semantic Web.
Within [XML Schema Datatypes], there is some lack of clarity as to
when two datatypes have values in common. There are also some minor
issues to do with whitespace that present themselves to the non-XML
developer. A further problem is that the datatypes QName,
ENTITY and ENTITIES
use the document context
within the lexical-to-value mapping.
Another aspect of the difference in concerns between
XML Schema datatypes and RDF datatyping is that XML is
primarily about syntactic forms, while RDF is primarily about
semantic values. The XML requirements have required XML Schema
datatypes to be clearer about the lexical forms of the datatypes
than about the values denoted.
In RDF, each datatype, when viewed as
an RDF Schema class, is treated as the set of values in the value space.
Hence, the rdfs:subClassOf relationship holds between two datatypes if
and only
if their value spaces are related by set inclusion.
A further problem, particulate pertinent to the Web Ontology Language (OWL),
(see the
example in the [OWL Guide])
is to do with how to refer to user defined XML Schema datatypes, using
a URI.
This document has the following aims:
- Clarify the relationships between the value spaces
of the 19 built-in primitive datatypes, and the 25 built-in
derived datatypes.
- Clarify the value space and lexical-to-value mappings
of anyURI and normalizedString
- Clarify the position of QName within
RDF datatyping.
- Provide URI references to refer to some user defined XML
schema datatypes.
The number 1 occurs in almost all of the numeric
simple types in XML Schema.
With each of the definitions of the value space of
the primitive types (float, decimal, double)
there is no indication that anything other than the
number that we learnt when we were in kindergarden
is intended.
Each derived numeric type has a value space that
is a subset of that of decimal. Thus, except for nonPositiveInteger
and negativeInteger, the very same number 1, belongs to the value space.
This example shows that it is a meaningful question as to which built-in
types have members in common. Moreover, examples from OWL can easily be
constructed whose consistency depends on being able to answer questions
as to whether a particular value is or is not equal to some other
particular value.
We note that the lexical-form "1" participates in the lexical space
of many of the non-numeric types.
However, in none of these does it map to a number, and hence
from the perspective of values, is distinct.
There is a set of numeric datatypes whose value spaces can be put
in a subclass hierarchy. There is a set of datatypes whose values
are strings, which also can be put in a subclass hierarchy.
The three datatypes which have lists of strings as their values
also form a hierarchy.
The two datatypes base64Binary and hexBinary share the
same value space; as do the two datatypes QName and NOTATION.
All of these spaces and all the other value spaces for each of the
built-in datatypes are pairwise disjoint.
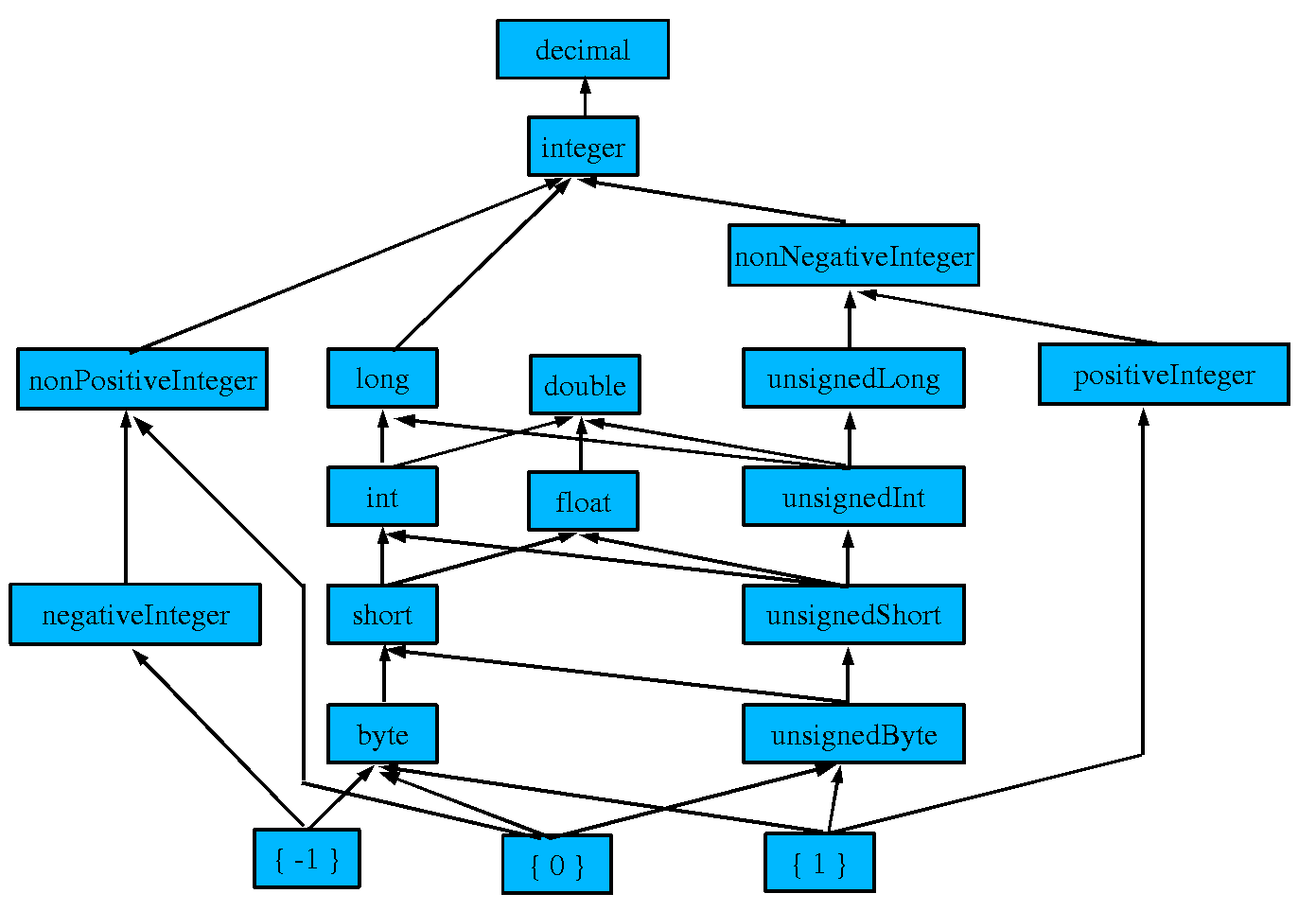
Moreover, by adding the three singleton sets { 1 }, { 0 }, and { -1 }
to the subclass hierarchies, the pictures reveal all the relevant subclass
and intersection relationships.
In the five figures below two built-in datatypes
-
have equal value spaces
-
If and only if they are in the same box.
-
have value spaces in a subset relationship
-
If and only if their is a line leading upwards from one
to the other (possibly via intermediate datatypes).
-
have members in common
-
If and only if they have a common subset in the diagram.
In other words the five diagrams completely capture the
subset relationships which hold between the value spaces,
or equivalently, the rdfs:subClassOf relationships between
the corresponding rdfs:Class-es.
We demonstrate the correctness of
the numeric hierarchy, and the string hierarchy.
A type derived by restriction, by
definition has a "value space and/or its lexical space" constrained
"to a subset of its base type".
We read this as implying that
[D] a type
derived by restriction always has a value space which is
a subset of that of its base type.
A numeric type is either derived from decimal, or
is float or double.
All the decimal values are rational numbers.
The values of float and double are some rational numbers and the five
special values positive and negative zero, positive and negative
infinity and not-a-number.
Some of the numeric types have finite cardinality
some are countably infinite.
We observe that
[K]
a countably infinite set cannot be a subset of a finite one.
[P] For each of the subset relationships
indicated in figure 1, the inverse relationship does not hold. (i.e. the relationships
are proper).. To see this consider the members:
0.5 of decimal, of float, and of double;
-1 of integer;
1000000000000000000000000 of integer and of nonNegativeInteger;
0 of nonPositiveInteger and of nonNegativeInteger;
10000000000 of long and unsignedLong;
1000000 of int and of unsignedInt;
1000 of short and of unsignedShort;
-2 of negativeInteger and of byte;
2 of positiveInteger and of byte and of unsignedByte;
and the smallest positive value, other than positive zero, in the value space of double.
[1] The value 1 is in the
value space of byte, unsignedByte and positiveInteger.
It is not in the value space of nonPositiveInteger.
[0] The value 0 is in the
value space of byte, unsignedByte, nonPositiveInteger.
It is not in the value space of positiveInteger or negativeInteger.
[-1] The value -1 is in the
value space of byte, negativeInteger.
It is not in the value space of nonNegativeInteger.
[U] The value spaces of
unsignedByte, unsignedShort, unsignedInt are subset of
the value spaces of short, int, and long, respectively.
This can be seen by comparing the maxInclusive and
minInclusive facets in each pair of datatypes.
[V] The value spaces of
unsignedByte, unsignedShort, unsignedInt, unsignedLong are not
subsets of
the value spaces of byte, short, int, and long, respectively.
This can be seen by considering the maxInclusive value in the unsigned
value spaces in each pair of datatypes.
[F] The value space of
float is a subset of that of double.
The definitions of the two value spaces are word for word identical except that the
word float is replaced by the word double and the constants
24, -149 and 104 are replaced by the constants 53, -1075 and 970.
Moreover 24 < 53; -1075 < -149 and 104 < 970.
[X] The value spaces of
both
int and unsignedInt are subsets of that of double.
Seen by setting e and m (from the definition of the value space of double)
to be respectively 0 and an arbitrary integer value from the value space of
int or unsignedInt.
[Y] The value spaces of
both
short and unsignedShort is a subset of that of float.
Seen by setting e and m (from the definition of the value space of float)
to be respectively 0 and an arbitrary integer value from the value space of
short or unsignedShort.
[Z]
There are long, unsignedLong, int and unsignedInt values that are not
in the value space of double, double, float
and float, respectively.
Specifically, 9223372036854775807 and 2147483647.
[I]
The special value positive infinity is in the value space of
float, but not of decimal.
Putting the previous results together we have the
following table, where the red cells show that the row datatype
is not a subset of the column datatype, and green cells show that the
row datatype is a subset of the column datatype.
Each cell is hyperlinked to the proof.
[T] We can apply transitive closure
rules to the subset relationship.
The following rules are applied repeatedly.
-
If A is a subset of B, and B is a subset of C then
A is a subset of C.
-
If A is a subset of B, and A is not a subset of C then
B is not a subset of C.
-
If B is a subset of C, and A is not a subset of C then
A is not a subset of B.
The resulting table is:
As discussed below: this document takes
the whiteSpace facet to be a constraint on the lexical
space of datatypes; the
lexical-to-value mapping of
normalizedString to be the identity, and #xA to be excluded
from its lexical space; and anyURI to
have string values and exclude certain
patterns of whitespace.
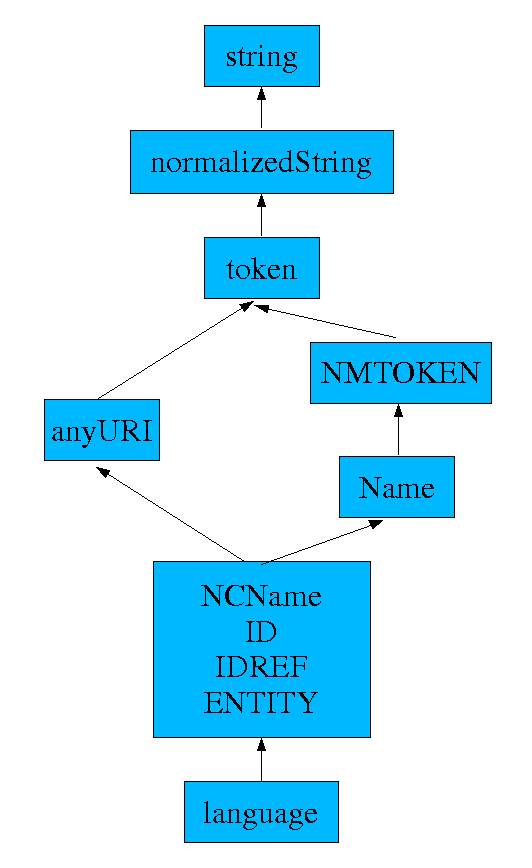
With these assumptions, the string valued types are those derived from
string and anyURI.
Moreover a combination of the
pattern and
whiteSpace
facets are used to constrain the lexical space.
Since the lexical-to-value mapping is the identity, every constraint on the
lexical space is an identical constraint on the value space.
Looking at the
whiteSpace facet, we find:
- One datatype string with value preserve.
- One datatype normalizedString with value replace.
- All the other datatypes have value collapse
Since string, normalizedString and token are not further constrained,
these three value spaces are supersets of all the other string value spaces, moreover
token is a subset of the other two, and normalizedString a subset of string.
By comparing the pattern (or by comparing the relevant
productions in [XML]) we observe that the value space of
Name is a subset of that of NMTOKEN.
Thus, (considering also the general result on derived
datatypes), we have a decreasing sequence of value spaces:
string, normalizedString, token, NMTOKEN, Name,
NCName. This a strictly monotonic decreasing sequence; strictness follows
from the strings "
", " ", "aȋ", "2", "a:b"
(with character references expanded).
The types derived by restriction from NCName are ID, IDREF, ENTITY.
In all three cases there are no facets used in the restriction, and so the four value
spaces are identical.
language is derived from token.
However, the pattern does not permit white space, and matches the
NCName
production.
Thus the value space of language is a subset of that of that of NCName.
Moreover the string "é" shows that this is a proper subset.
Every NCName can be converted into a relative URI by the %-escaping
algorithm, hence the value space of NCName is a subset of that
of anyURI. However the Name "a:" is unchanged by %-escaping,
and is not a URI.
When combined with transitivity considerations,
these observations are equivalent to the earlier
diagram of the string value types.
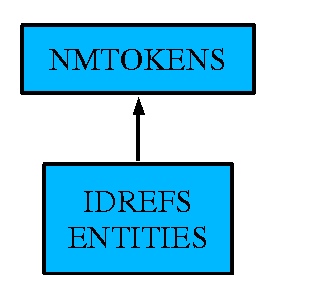
Three datatypes IDREFS, ENTITIES and NMTOKENS are
derived by list
from string valued types.
The relationships between their value spaces mirror the relationships
between the value spaces of their
itemTypes.
Three of the XML Schema datatypes depend on the
surrounding document context.
These are:
- QName
- The mapping … requires a namespace declaration
to be in scope …
- ENTITY
- ENTITIES
- The *value space* … is scoped to a specific instance document.
These are not suitable for use in RDF.
Moreover, NOTATION is an abstract type and cannot be used
directly. Its subtypes provide an explicit lexical-to-value
mapping using the
notation
element.
Above, we have considered many of the XML Schema built-in datatypes: all the numeric types,
all the string valued types, and all the
list of string valued types.
In this section we list the other types, and the brief definition of
their value spaces.
Of these: the value spaces of hexBinary and of base64Binary are the same; and
the value spaces of QName and of NOTATION are the same.
All the others are different and non-overlapping.
The zero length sequence might be considered a common member to
the value space of
hexBinary, string (and some of its derived types), IDREFS (and the other
list valued built-in types).
Within [DAML+OIL], URIs for user-defined simple types are
created by concatenating the URL of the definition file, the
string "#", and the name of the type.
The [OWL Requirements] includes a
Range constraint objective: "The language should support the ability to specify ranges of values"
Meeting this objective, using [XML Schema Datatypes] within RDF,
requires the use of URIs for user-defined datatypes.
There is a
proposal to bless the DAML+OIL mechanism.
If this is to be done, it makes more sense for RDF Core WG to do it; and
it would make more sense still for XML Schema WG to do it.
As a stop gap, before the [NUN] work is finished, something
that binds a URI reference to a user-defined datatype under tight constraints
would suffice (e.g. that the targetNamespace is the URL of the defining file,
that the simpleType is a top-level type, that there is no content other
than simpleTypes etc. etc.).
It is unlikely that we will see RDF reasoners that are complete with respect
to datatype reasoning. This is the case, even if we restrict attention to those
relationships shown here which are non-controversial (i.e. between the numeric types
excluding float and double, and between the string types excluding anyURI).
Concerns about implementability
appear to be the major motivation for the XML Schema WG's rejection of
their earlier
real datatype as the supertype of all numbers,
(cf.
member e-mail
public e-mail).
The definition is
[Definition:]
whiteSpace constrains the ·value space·
of types ·derived· from
string such that
the various behaviors
specified in Attribute Value Normalization
in [XML 1.0 (Second Edition)] are realized. The value of
whiteSpace must be one of {preserve, replace, collapse}.
This is an unfortunate wording.
It leaves open possibilities such as:
- There is no constraint. Attribute Value Normalization
leaves all character references unchanged, so arbitrary string
values can be encoded.
- The constraint is only on the value space. The lexical-to-value mapping
is changed to realized the desired whitespace normalization. This reading
would have the string " 1" being a member of the lexical space of
int, which is then trimmed before being mapped to the integer one.
It also says nothing about its effect on types other than those derived from string.
To understand this definition, it is beneficial to
look at the
process described in
section 3.1.4 White Space Normalization during Validation
of
[XML Schema Structures].
My understanding is that the normalization described there is
applied before the lexical-to-value mapping that occurs in datatyping.
In this document we assume that the intended meaning
is something like:
[Definition:]
whiteSpace constrains the ·lexical space·
of types. The value of
whiteSpace must be one of {preserve, replace, collapse}.
If the value is replace or collapse then the string does not contain
any characters
#x9 (tab), #xA (line feed) and #xD (carriage return).
If the value is collapse then the string neither starts nor ends with character
#x20 (space), nor does it contain two consecutive #x20 (space) characters.
The contrast between this text and the original text is that between a
declaractive definition that leaves procedural issues unclear, and a procedural
definition that leaves declarative issues unclear.
The lexical-to-value mapping of string is the identity function.
normalizedString is derived from string.
Therefore the lexical-to-value mapping of normalizedString
is also the identity function.
However, in the defintion, the value space does not contain strings with
the line feed character #xA, whereas the lexical space does.
This suggest the question, "For the one character string '#xA' in the
lexical space of normalizedString, what is the corresponding value?"
Given the reading of whiteSpace as a constraining facet
(see above), and noting that
for normalizedString, that the whiteSpace facet has value
replace, then this seems like an error. We read the lexical
space of normalizedString to exclude #xA.
This is similar to
erratum 2-17.
A distinctive aspect of the definition of anyURI is that
the format of clearly defining both the lexical and value spaces is not followed.
As a result, it is unclear what either is.
The [XLink]
Locator Attribute
text is the key definition, and this talks about an escaping
"procedure [which] is applied when passing the URI reference to a URI resolver."
Since the lexical-to-value mapping does not involve resolving the URI,
I take the value space to be a set of strings to which this procedure could
be applied (but is not).
This is consistent with the following phrase:
"For anyURI, length is measured in units of
characters (as for string)."
found in the
discussion on length, which is applied to values in the value spaces.
The lexical and value spaces effectively are identified, and
the lexical-to-value mapping is the identity function.
The constraining facet whiteSpace for anyURI in
the
Schema for Datatype Definitions is given as collapse.
This constrains the values of anyURI to exclude #xA, #xD, #x9
and consecutive pairs of #x20; as well as initial and final #x20.
These constraints are not however clearly articulated in the definition of
anyURI. For example, the XLink text for the value of the attribute xlink:href
does not exclude any of these (remembering that attribute value normalization can
be circumvented by the use of character references). Note that in the
Sample
DTD for [XLink], xlink:href has attribute type CDATA.
See
section 4.2.1 of [XML Schema Datatypes]; also
E2-30.
The original text says:
Note that a consequence of the above is that, given ·value space·
A and
·value space·
B where A and
B are not related by ·restriction·
or ·union·,
for every pair of values a from
A and b from
B, a != b.
Given that the earlier text is clear that:
- A
·value space·
is "the set of values".
-
That
[Definition:] Atomic datatypes
are those having values which are regarded by this specification as
being indivisible.
-
That
The basic ·value space·
of double consists of the values
m × 2^e, where m
is an integer whose absolute value is less than
2^53, and e is an
integer between -1075 and 970, inclusive.
-
That
The ·value space· of decimal
is the set of the values i × 10^-n,
where i and n are integers
such that n >= 0.
We can substitute "double" for A, "decimal" for B,
and 1 (the first positive integer) for both a and b and see that we should:
Note that a consequence of the above is that, given [the] ·value space·
of double and [the]
·value space·
of decimal where double and
decimal are not related by ·restriction·
or ·union·,
for [the] pair of values 1 from
double and 1 from
decimal [my emphasis], 1 != 1.
The emphasised phrase at the end suggests that this note should not be taken
at face value, but in fact serves to show that the "equality" being talked about
is misnamed. It appears to be a type-specific equality between two pairs rather than
between two indivisable values. These note could perhaps be rephrased to suggest that
1 when regarded as a double is not type-equal to 1 when regarded as a
decimal. As it is, it is simply in error.
The correction in
E2-30 makes the matter worse, by turning the error from being in a non-normative
note that fails to clarify the other text, into a normative (but false) assertion:
"The value spaces of the primitive datatypes are disjoint (they do not share any values)."
This seems to reflect a tension between the declarative body of the datatypes work, and
the equal facet which appears to be motivated by the need to support some
processing in
[XML Schema Structures].
From
section 3.11.1
"The comparison between keyref {fields} and key or unique {fields} is by value equality, not by string equality."
A possible change, which would reduce possible confusion with mathematical equality
is to rename the equality function
in both places, to something like "typed-equality" which would compare
two pairs;
each pair being a datatype and a value from its value space.
These would compare equal
if the two values compared equal and the two datatypes were both
derived from the same primitive type.
A further problematic example from the text is the definition of the value
space of NOTATION.
The ·value space·
of NOTATION is the set QNames.
This flatly contradicts the assertion that the value spaces are disjoint.
- [XML Schema Datatypes]
-
http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/
- [XML Schema Structures]
-
http://www.w3.org/TR/2001/REC-xmlschema-1-20010502/
- [RDF Concepts]
-
http://www.w3.org/TR/2002/WD-rdf-concepts-20021108/
- [OWL Guide]
-
http://www.w3.org/TR/2002/WD-owl-guide-20021104/
- [OWL Requirements]
-
http://www.w3.org/TR/2002/WD-webont-req-20020708/
- [DAML+OIL]
-
http://www.w3.org/Submission/2001/12/
- [XML]
-
http://www.w3.org/TR/2000/REC-xml-20001006
- [XLink]
-
http://www.w3.org/TR/2001/REC-xlink-20010627/
- [NUN]
-
http://lists.w3.org/Archives/Member/w3c-xml-schema-ig/2002Oct/att-0050/01-part