- From: Patrick Stickler <patrick.stickler@nokia.com>
- Date: Fri, 11 Jan 2002 09:29:47 +0200
- To: ext Graham Klyne <GK@NineByNine.org>, Jeremy Carroll <jjc@hplb.hpl.hp.com>
- CC: Sergey Melnik <melnik@db.stanford.edu>, RDF Core <w3c-rdfcore-wg@w3.org>
- Message-ID: <B864610C.B61D%patrick.stickler@nokia.com>
On 2002-01-11 2:10, "ext Graham Klyne" <GK@NineByNine.org> wrote:
>> - Needing three URIs for each datatype.
>> Seems a bit like needing to talk about "Jeremy's body", "Jeremy's
> soul"
>> and "Jeremy' mind". Might be useful sometimes, but plain "Jeremy" will
> get
>> you a long way. I suppose RDF is about triples!
>
> ...
> We need to start from a place where the meaning of a URI is
> well-defined,
> so if we need to make statements about three different aspects of some
> entity I submit that we need three different names. I'm sceptical that
> we
> can talk effectively about a data type and its representations with just
> one name.
I have no problems with the MT and other conceptual discussion talking
about all three components of a data type. Obviously, those components
must have names and we must be able to refer to them unambiguously.
But once you have defined data types as Sergey has done in section 2,
and once you have a pairing of lexical form and the identity of the
data type as a whole, it is totally unambiguous which value in the
value space is denoted by that pairing.
Thus, the representation of data typing in the graph need only concern
itself with the pairing of lexical form and data type identity, not
with the identities of the components of the data type.
If the .map, .lex, .val, and .cmap suffixes were employed solely as
language of the theory and not actual URIs then perhaps we all could
be satisfied?
I.e.,
1. Take up to section 4.1 as a starting point (rework section 3 and
remove sections 4.2 onwards, including section 5).
2. Add math in or following section 4.1 that states that for any pairing
(lexical_form, data_type_URIref)
there is one and only one mapping
(lexical_form, data_value)
between the lexical space and value space of that data type.
Surely the math for this is straightforward (I wish I could provide it).
3. Add final sections detailing the idioms P and D, how they define such
pairings of lexical form and data type.
And we're done.
Note (and this is *VERY* significant): neither P nor D are the data typing
solution! Nor is there theory or math specific to P or D. P and D are just
idioms for expressing such pairings. The actual data typing model is just
the pairings, independent of idiom. The total data typing solution is the
model of pairings, along with two official, recommended, "blessed" idioms;
one for local typing and one for global typing.
This separation of model from idiom also allows us to later evolve/expand
to other idioms, such as P+, U, etc. (even S A/B if so desired) without
having to touch the MT. So long as a given exRDF application understands
a particular idiom -- how the idiom defines such pairings, the MT based
interpretation crystal clear. And a given API can provide a unified
interface to multiple idioms, providing a consistent pairing-based view
of typed data literals.
>> - Having two incompatible usage idioms (two compatible idioms would
> somehow
>> be less cumbersome).
>
> I don't see any incompatible idioms here. Just different idioms.
> ...
> How are they (A and B) not compatible?
See my examples from yesterday:
http://lists.w3.org/Archives/Public/w3c-rdfcore-wg/2002Jan/0045.html
> If this group doesn't end up with something that is well-grounded in
> some
> appropriate formalism, I think we'll have wasted our time.
Agreed, but being well-grounded is not the *only* important
consideration. Ease-of-use is equally (I would argue even slightly
more) important.
> I'm still open to other worked-out proposals that hide this
> value/lexical
> distinction, but I'm concerned that we'll spin indefinitely for wont of
> a
> solid proposal.
I have made the same basic proposal given above several times. No, it has
not been expressed mathematically, but even in the absence of the math,
it should be reasonably clear and "solid". To refresh folks memories, c.f.
http://lists.w3.org/Archives/Public/w3c-rdfcore-wg/2001Nov/0579.html
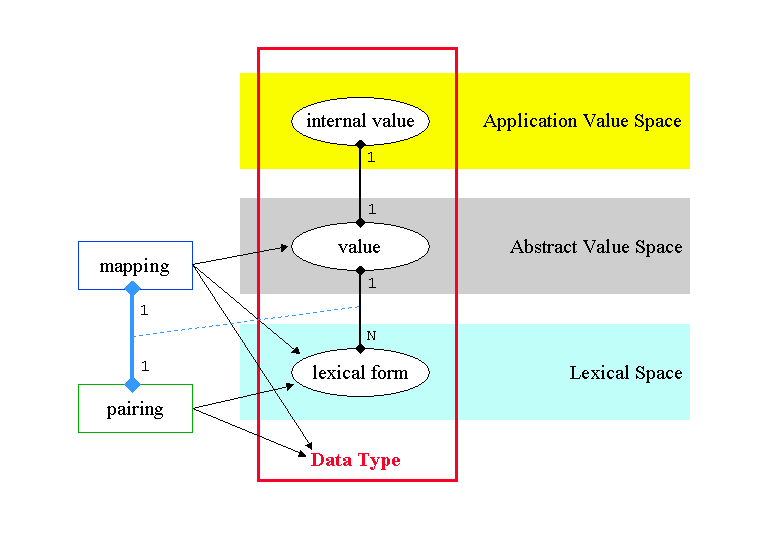
Also, attached is a diagram I drew a few weeks back that illustrates
the relationships between mappings and pairings.
If the above two resources are not clear, then I will (again) be happy
to explain them further -- unfortunately, sans the math.
Perhaps some brave soul out there who has the ability would like to take
a stab at the math for the pairing-based model I am trying very hard to
express in this troublesome and slippery natural language?
Cheers,
Patrick
--
Patrick Stickler Phone: +358 50 483 9453
Senior Research Scientist Fax: +358 7180 35409
Nokia Research Center Email: patrick.stickler@nokia.com
Attachments
- application/octet-stream attachment: data-types.png
{kind=link}
Received on Friday, 11 January 2002 02:29:07 UTC