- From: Martin Hepp <martin.hepp@ebusiness-unibw.org>
- Date: Tue, 17 Apr 2012 17:43:52 +0200
- To: Peter Mika <pmika@yahoo-inc.com>
- Cc: "public-vocabs@w3.org Vocabularies" <public-vocabs@w3.org>, "public-lod@w3.org" <public-lod@w3.org>, Chris Bizer <chris@bizer.de>
- Message-Id: <4AB6CB08-FC5C-458C-A501-18958622E14E@ebusiness-unibw.org>
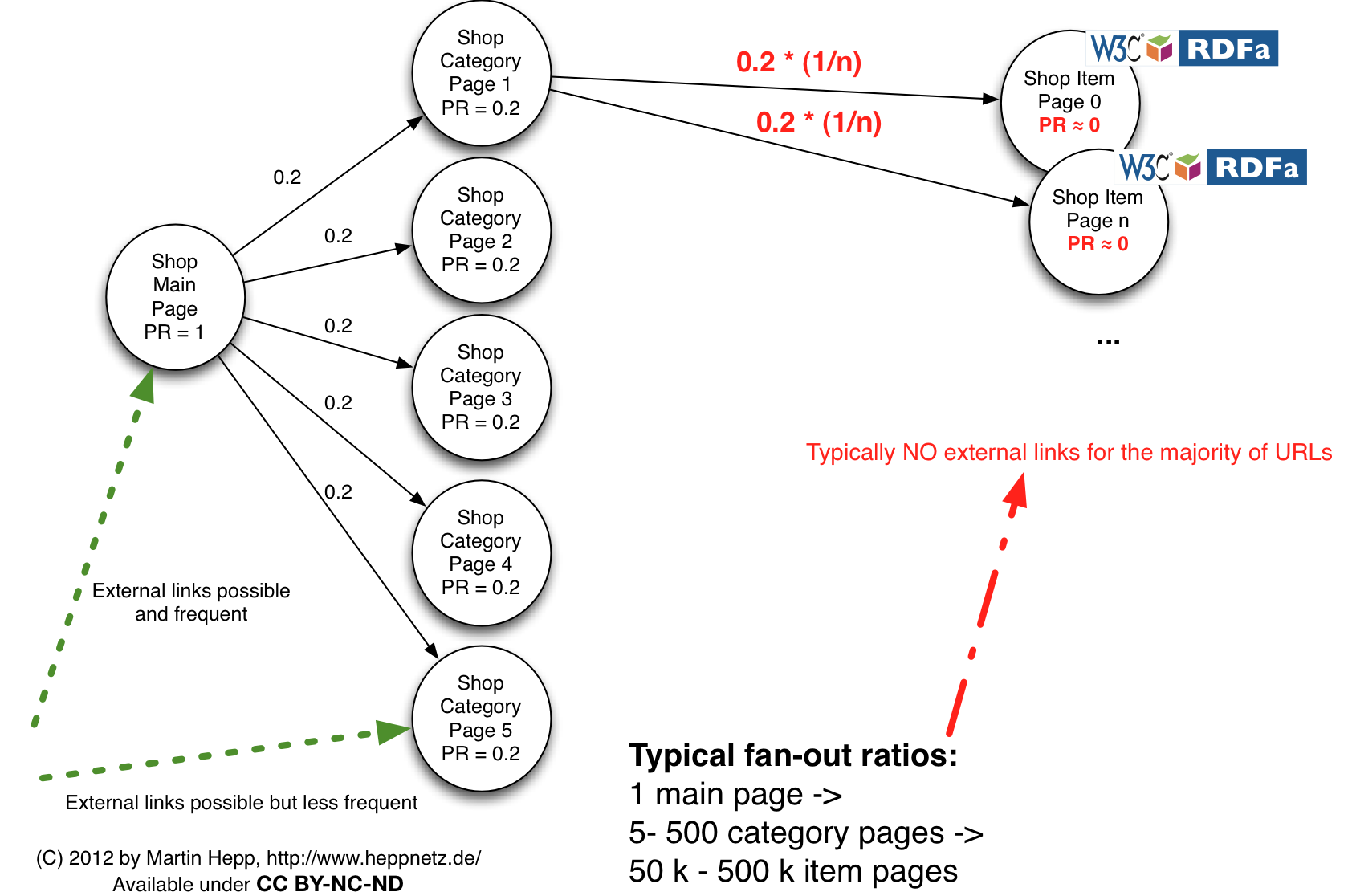
Hi Peter, Thanks for your feedback. However, > PageRank does transfer along the edges of the web graph, so a highly ranked homepage would transfer it's PageRank to the pages leading from it. Do you mean that if http://wayfair.com/ can pass along its pagerank to all of its 2,000,000 sub-pages *in parallel*? I had understood from the algorithm (e.g. [1]) that "The PageRank transferred from a given page to the targets of its outbound links upon the next iteration *is divided equally among all outbound links.*" which means that a shop main page with a pagerank of say 1 would only transfer a fraction of this, i.e. 1 / 2,000,000 = 0.0000005 to each of the "deep" links. So the typical scenario will be as shown in the attached illustration, which PR of close to zero for deep links. This would also explain my earlier observation from [2]. You can also see from a brief look at the entity types found in the stats that they find prominently those that also make sense on the main and category pages. The Data Web does not happen on the landing pages and their nearest neighbors, so the CommonCrawl corpus in its current form is useless for making any statements about the data exposed on the Web. Best Martin [1] http://en.wikipedia.org/wiki/PageRank [2] http://lists.w3.org/Archives/Public/public-vocabs/2012Mar/0095.html
On Apr 17, 2012, at 4:49 PM, Peter Mika wrote:
> Hi Martin,
>
> By incorporating PageRank into the decision of what pages to crawl, CommonCrawl is actually trying to approximate what search engine crawlers are doing. In general, search engines would collect pages that would be more likely to rank higher in search results, and PageRank is an important component of that.
>
> PageRank does transfer along the edges of the web graph, so a highly ranked homepage would transfer it's PageRank to the pages leading from it.
>
> My only complaints about CommonCrawl in this regard is that they don't publish their webgraph and the computed scores. It's a valuable resource to have. Further, they should compute it regularly... it seems they have two dumps with two years apart, and if they used the PageRank scores from the first dump to crawl the second, that might be a bit off.
>
> Cheers,
> Peter
>
>
>
> On 4/17/12 3:25 PM, Martin Hepp wrote:
>> Dear Chris, all,
>>
>> while reading the paper [1] I think I found a possible explanation why WebDataCommons.org does not fulfill the high expectations regarding the completeness and coverage.
>>
>> It seems that CommonCrawl filters pages by Pagerank in order to determine the feasible subset of URIs for the crawl. While this may be okay for a generic Web crawl, for linguistics purposes, or for training machine-learning components, it is a dead end if you want to extract structured data, since the interesting markup typically resides in the *deep links* of dynamic Web applications, e.g. the product item pages in shops, the individual event pages in ticket systems, etc.
>>
>> Those pages often have a very low Pagerank, even when they are part of very prestigious Web sites with a high Pagerank for the main landing page.
>>
>> Example:
>>
>> 1. Main page: http://www.wayfair.com/
>> --> Pagerank 5 of 10
>>
>> 2. Category page: http://www.wayfair.com/Lighting-C77859.html
>> --> Pagerank 3 of 10
>>
>> 3. Item page: http://www.wayfair.com/Golden-Lighting-Cerchi-Flush-Mount-in-Chrome-1030-FM-CH-GNL1849.html
>> --> Pagerank of 0 / 10
>>
>> Now, the RDFa on this site is in the 2 Million item pages only. Filtering out the deep link in the original crawl means you are removing the HTML that contains the actual data.
>>
>> In your paper [1], you kind of downplay that limitation by saying that this approach yielded "snapshots of the popular part of the web.". I think "popular" is very misleading in here because the Pagerank does not work very well for the "deep" Web, because those pages are typically lacking external links almost completely, and due to their huge number per site, they earn only a minimal Pagerank from their main site, which provides the link or links.
>>
>> So, once again, I think your approach is NOT suitable for yielding a corpus of usable data at Web scale, and the statistics you derive are likely very much skewed, because you look only at landing pages and popular overview pages of sites, while the real data is in HTML pages not contained in the basic crawl.
>>
>> Please interprete your findings in the light of these limitations. I am saying this so strongly because I already saw many tweets cherishing the paper as "now we have the definitive statistics on structured data on the Web".
>>
>>
>> Best wishes
>>
>> Martin
>>
>> Note: For estimating the Pagerank in this example, I used the online-service [2], which may provide only an approximation.
>>
>>
>> [1] http://events.linkeddata.org/ldow2012/papers/ldow2012-inv-paper-2.pdf
>>
>> [2] http://www.prchecker.info/check_page_rank.php
>>
>> --------------------------------------------------------
>> martin hepp
>> e-business& web science research group
>> universitaet der bundeswehr muenchen
>>
>> e-mail: hepp@ebusiness-unibw.org
>> phone: +49-(0)89-6004-4217
>> fax: +49-(0)89-6004-4620
>> www: http://www.unibw.de/ebusiness/ (group)
>> http://www.heppnetz.de/ (personal)
>> skype: mfhepp
>> twitter: mfhepp
>>
>> Check out GoodRelations for E-Commerce on the Web of Linked Data!
>> =================================================================
>> * Project Main Page: http://purl.org/goodrelations/
>>
>>
>
>
--------------------------------------------------------
martin hepp
e-business & web science research group
universitaet der bundeswehr muenchen
e-mail: hepp@ebusiness-unibw.org
phone: +49-(0)89-6004-4217
fax: +49-(0)89-6004-4620
www: http://www.unibw.de/ebusiness/ (group)
http://www.heppnetz.de/ (personal)
skype: mfhepp
twitter: mfhepp
Check out GoodRelations for E-Commerce on the Web of Linked Data!
=================================================================
* Project Main Page: http://purl.org/goodrelations/
Attachments
- image/png attachment: why-webdatacommons-sucks.png
Received on Tuesday, 17 April 2012 15:44:30 UTC