- From: <hha1@cornell.edu>
- Date: Tue, 6 Oct 2015 22:04:41 +0000 (UTC)
- To: "Young,Jeff (OR)" <jyoung@oclc.org>, Sean Petiya <spetiya1@kent.edu>
- Cc: "public-schemabibex@w3.org" <public-schemabibex@w3.org>
- Message-ID: <1012449544.1604129.1444169081813.JavaMail.yahoo@mail.yahoo.com>
I'm glad you said that- I was having some philosophical difficulties with the whole "there is no suitable representation for those resources" thing. The representation is never the resource- that's why it's called a representation :-) It may be a good or bad representation, or a complete or incomplete one, but it's still a representation. You obviously can't completely represent all aspects of a person in RDF, but that doesn't mean that an RDF document describing a person is not a representation.
One of the most important steps in putting together a prior REST architecture that I worked on was the decision to be very clear about resource vs representation. When we stopped calling *everything* "resource" and started calling the documents "representations" a lot of confusion went away.
For using fragment URIs, in my mind the fragment always represents some portion of the whole document. It could not represent something described in a document more directly than the portion of the document already does (so in the RDF example, we're still looking at an RDF document, just a smaller one that the client has to extract after retrieving the full document from the server). I did a lot of stuff using JSON-pointer fragments with JSON representations per RFC 6901 - JavaScript Object Notation (JSON) Pointer
| |
| | | | | |
| RFC 6901 - JavaScript Object Notation (JSON) Pointer[Docs] [txt|pdf] [draft-ietf-appsaw...] [Diff1] [Diff2] [Errata] PROPOSED STANDARD Errata Exist Internet Engineering Task Force (IETF) P. Bryan, Ed. |
| |
| View on tools.ietf.org | Preview by Yahoo |
| |
| |
thanks,-henry
From: "Young,Jeff (OR)" <jyoung@oclc.org>
To: "hha1@cornell.edu" <hha1@cornell.edu>; Sean Petiya <spetiya1@kent.edu>
Cc: "public-schemabibex@w3.org" <public-schemabibex@w3.org>
Sent: Tuesday, October 6, 2015 2:14 PM
Subject: RE: Uniquely identifying series and issues
#yiv4270132077 #yiv4270132077 -- _filtered #yiv4270132077 {font-family:Helvetica;panose-1:2 11 6 4 2 2 2 2 2 4;} _filtered #yiv4270132077 {panose-1:2 4 5 3 5 4 6 3 2 4;} _filtered #yiv4270132077 {font-family:Calibri;panose-1:2 15 5 2 2 2 4 3 2 4;}#yiv4270132077 #yiv4270132077 p.yiv4270132077MsoNormal, #yiv4270132077 li.yiv4270132077MsoNormal, #yiv4270132077 div.yiv4270132077MsoNormal {margin:0in;margin-bottom:.0001pt;font-size:12.0pt;}#yiv4270132077 a:link, #yiv4270132077 span.yiv4270132077MsoHyperlink {color:blue;text-decoration:underline;}#yiv4270132077 a:visited, #yiv4270132077 span.yiv4270132077MsoHyperlinkFollowed {color:purple;text-decoration:underline;}#yiv4270132077 p.yiv4270132077msonormal, #yiv4270132077 li.yiv4270132077msonormal, #yiv4270132077 div.yiv4270132077msonormal {margin-right:0in;margin-left:0in;font-size:12.0pt;}#yiv4270132077 p.yiv4270132077msolistparagraph, #yiv4270132077 li.yiv4270132077msolistparagraph, #yiv4270132077 div.yiv4270132077msolistparagraph {margin-right:0in;margin-left:0in;font-size:12.0pt;}#yiv4270132077 p.yiv4270132077msochpdefault, #yiv4270132077 li.yiv4270132077msochpdefault, #yiv4270132077 div.yiv4270132077msochpdefault {margin-right:0in;margin-left:0in;font-size:12.0pt;}#yiv4270132077 span.yiv4270132077msohyperlink {}#yiv4270132077 span.yiv4270132077msohyperlinkfollowed {}#yiv4270132077 span.yiv4270132077emailstyle18 {}#yiv4270132077 span.yiv4270132077emailstyle20 {}#yiv4270132077 p.yiv4270132077msonormal1, #yiv4270132077 li.yiv4270132077msonormal1, #yiv4270132077 div.yiv4270132077msonormal1 {margin:0in;margin-bottom:.0001pt;font-size:12.0pt;}#yiv4270132077 span.yiv4270132077msohyperlink1 {color:blue;text-decoration:underline;}#yiv4270132077 span.yiv4270132077msohyperlinkfollowed1 {color:purple;text-decoration:underline;}#yiv4270132077 p.yiv4270132077msolistparagraph1, #yiv4270132077 li.yiv4270132077msolistparagraph1, #yiv4270132077 div.yiv4270132077msolistparagraph1 {margin-top:0in;margin-right:0in;margin-bottom:0in;margin-left:.5in;margin-bottom:.0001pt;font-size:12.0pt;}#yiv4270132077 span.yiv4270132077emailstyle181 {color:#1F497D;}#yiv4270132077 span.yiv4270132077emailstyle201 {color:windowtext;}#yiv4270132077 p.yiv4270132077msochpdefault1, #yiv4270132077 li.yiv4270132077msochpdefault1, #yiv4270132077 div.yiv4270132077msochpdefault1 {margin-right:0in;margin-left:0in;font-size:10.0pt;}#yiv4270132077 span {}#yiv4270132077 span.yiv4270132077EmailStyle32 {color:#1F497D;}#yiv4270132077 .yiv4270132077MsoChpDefault {font-size:10.0pt;} _filtered #yiv4270132077 {margin:1.0in 1.0in 1.0in 1.0in;}#yiv4270132077 div.yiv4270132077WordSection1 {}#yiv4270132077 Keep in mind that the Cool URIs document was published back in 2008, when people were still skeptical about the “legality” of using http URIs for things that aren’t web pages (like printed comic books). Those days are mostly gone and the current mode of thinking is that the URI identifies what the RDF describes regardless of how the URI behaves at the protocol level. There are use cases that can benefit and regrets that can be avoided by being fussy, but in hindsight it was mostly a tempest in a teakettle. Jeff
From: hha1@cornell.edu [mailto:hha1@cornell.edu]
Sent: Tuesday, October 06, 2015 4:56 PM
To: Young,Jeff (OR); Sean Petiya
Cc: public-schemabibex@w3.org
Subject: Re: Uniquely identifying series and issues Django actually has an option (which we enable) to automatically redirect anything without a trailing slash to the same URL but with a trailing slash appended. Of course we would want to document the URLs that do not require a redirect and encourage API clients to use those for performance/efficiency reasons. I'm reading through the links you provided- more reply soon. thanks, -henry From: "Young,Jeff (OR)" <jyoung@oclc.org>
To: "hha1@cornell.edu" <hha1@cornell.edu>; Sean Petiya <spetiya1@kent.edu>
Cc: "public-schemabibex@w3.org" <public-schemabibex@w3.org>
Sent: Tuesday, October 6, 2015 7:04 AM
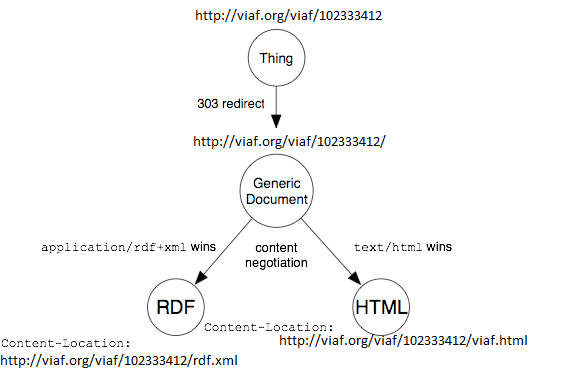
Subject: RE: Uniquely identifying series and issues I don’t know if Django can support 303 redirects, but the VIAF URI patterns might be a useful comparison. It uses this “Cool URI” pattern: http://www.w3.org/TR/cooluris/#r303gendocument In effect, the “generic document” is a graph. This pattern is a bit more engineered than the others but it has more flexibility, such as the ability to describe the graph (generic document) independently from the thing. Another nice thing about this “generic document” pattern is that you can piggy back hash URIs on the generic document URI and describe those things too, if you need to. http://www.w3.org/TR/cooluris/#hashuri Jeff From:hha1@cornell.edu [mailto:hha1@cornell.edu]
Sent: Tuesday, October 06, 2015 1:34 AM
To: Sean Petiya
Cc: public-schemabibex@w3.org
Subject: Re: Uniquely identifying series and issues I expect to provide a RESTful API, including HATEOAS, linking/relations, etc. I've done a good bit of work on RESTful API design before so I have some fairly concrete notions of how that works already. We're using Django underneath, so the only oddity of the URLs is that the canonical form always ends with a trailing "/". There's an argument that can be made that resources should not have a trailing "/" as they are things, not directories. I haven't decided if I want to drop the trailing "/" for REST URIs- if we were to use file extensions for content selection we would want to drop it. For the HTML web pages we'll want to leave them in place as those URLs are used in a fair number of places around the web now. I guess one question is whether to use the web site URIs or the API's URIs. I was not planning to enforce a direct correlation between the web site and the API. It may match in some places but not in others. The web pages canonically live atwww.comics.org, and I was vaguely planning on hosting the API at api.comics.org (all of this is provisional, btw- there's a group of tech folks and while I'm the only one working on the API, everything is subject to review by the group). I am planning to support different content formats selected with headers. I dislike using file extensions for content selection, partially because you can then have conflicting headers and extensions which annoys me a lot. The argument I've usually heard in favor of extensions is about being able to look at output in a browser by typing in a simple URL, but there are debugging tools that let you set headers in order to do that kind of thing (and you can set up a reasonable default content type). I'd be interested in hearing other counterarguments, though. The last time I had that discussion was a couple of years ago, so maybe there are newer best practices to consider. Any commentary on the above, while perhaps outside the scope of this mailing list, is welcome. thanks, -henry From: Sean Petiya <spetiya1@kent.edu>
To: hha1@cornell.edu
Cc: Dan Scott <denials@gmail.com>; "public-schemabibex@w3.org" <public-schemabibex@w3.org>
Sent: Monday, October 5, 2015 8:41 PM
Subject: Re: Uniquely identifying series and issues Actually, I think GCD URL's are good candidates for identifiers. They are extensionless, and meet the technical criteria for a URI. I'm not familiar with the GCD webserver configuration, but depending on how you plan to setup your API, Henry, you could serve negotiable content in a variety of formats from these same base URLs (Not sure what your specific plan is, or the technical requirements of your API, maybe its RESTful...). Here's just one basic approach---and an example from my comic book ontology---but you could pick almost any good Web vocabulary and do the same type of in-browser request for specific content types: URI ->https://comicmeta.org/cbo/Comic HTML -> https://comicmeta.org/cbo/Comic.html Turtle -> https://comicmeta.org/cbo/Comic.ttl JSON -> https://comicmeta.org/cbo/Comic.json If you were to follow this approach, your URLs would look like: URI ->http://www.comics.org/issue/899800 HTML->http://www.comics.org/issue/899800.html Turtle->http://www.comics.org/issue/899800.ttl JSON->http://www.comics.org/issue/899800.json Of course, even without the additional content types, the GCD URLs make good identifiers. I'd love to see library data referencing GCD identifies so that we could query for relationships like what specific comic issues and/or stories are contained in a collection of comics on a library shelf, such as in an omnibus or trade paperback. For example, relationships like: <http://www.worldcat.org/oclc/714725942> schema:hasPart <http://www.comics.org/issue/44703/> ...are especially useful to comic book fans and readers (i.e., "I need to read the Amazing Spiderman #302, where can I find it?"). I've fleshed out some of what I think this might look like in my thesis [1], and I have examples on GitHub [2] if you are interested. Although, fair warning, they are not schema.org specific or exclusive---but the basics I think would be applicable to your case. Dan Scott also has a great set of HTML/RDFaschema.org examples for comics that (I think) uses WorldCat identifiers, and if not it definitely used GCD URLs as identifiers--if I remember correctly. Unfortunately, I have lost the link---but maybe Dan can provide it? Good luck, and I'm excited to hear more! Sean Petiya [1] http://rave.ohiolink.edu/etdc/view?acc_num=kent1416791055 [2] https://github.com/seanpetiya/thesis On Mon, Oct 5, 2015 at 7:28 PM, <hha1@cornell.edu> wrote:
I think I answered this question (below) myself already- GCD URLs would be one source of URLs that could be used in the "sameAs" field from Thing. If I'm understanding that field's usage correctly now. I had originally taken it to be "same as" in some sort of same-type sense rather than an identity-defining sense. Learning curve... cheers, -henry From: "hha1@cornell.edu" <hha1@cornell.edu> When you use GCD URLs as examples here, are you thinking of people generally using our URLs for identification purposes, or that it would just be any URL (for instance from one of the other databases) and which source would depend on the user? thanks, -henry
Attachments
- image/png attachment: image001.png
Received on Tuesday, 6 October 2015 22:05:15 UTC