- From: Koji Ishii <kojiishi@gluesoft.co.jp>
- Date: Fri, 6 May 2011 01:25:14 -0400
- To: "Phillips, Addison" <addison@lab126.com>, "public-i18n-core@w3.org" <public-i18n-core@w3.org>
- Message-ID: <A592E245B36A8949BDB0A302B375FB4E0AC287560E@MAILR001.mail.lan>
While I agree with you for the most part and I like this:
> 1. Document that selectors are non-normalizing.
> Authors must be aware of content normalization concerns,
> especially for languages that are affected by normalization issues.
I can't agree with this:
> 2. Recommend that documents, including stylesheets,
> be saved in Unicode Normalization Form C.
> Potentially include a warning in the validators.
Because it can apply to displayable contents as well. As I said in the meeting, although I'm not very familiar with the technical details of the issue, some Unicode guys in Japan strongly recommends not to use NFC to any displayable contents. I'm asking him for more details, but here's one I found. These rows show different glyphs for the source (left) and the result of NFC/NFD/NFKC/NFKD (right):
[cid:image001.png@01CC0BF5.B44474A0]
http://homepage1.nifty.com/nomenclator/unicode/normalization.htm#ci (Japanese page)
Other rows in the table might be different as well given its context, but I can’t see differences in my environment; maybe it can vary by font? I’m not sure at this point.
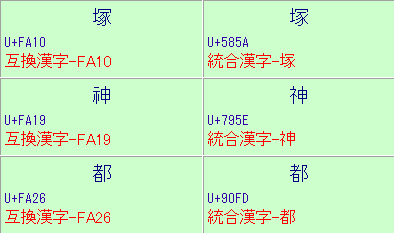
There’re some pages that says it also impacts non-ideographic characters:
[cid:image002.gif@01CC0BF8.2B0D7940]
http://blog.antenna.co.jp/PDFTool/archives/2006/02/pdf_41.html (Japanese page)
I’m not sure how important these two differences are for people who use these characters though.
So, I think it’s a trade-off between:
1. String matching-time late normalization; impact on CSS/japascript engines and compatibilities
2. Recommend to save in NFC; authors can no longer use some ideographic characters
3. As is; impact on Vietnamese (did you say so? Or are there more scripts?)
I take id and class name are just like variable name of javascript or any other programming language, which isn’t usually normalized. Therefore my preference in order is 3, and then 1.
The other possible option is to recommend to use ASCII for strings that other authors may refer to, such as id or class name. I think such general rule works well for global variables in programming languages. I’m not sure how this sounds unfair to Vietnamese users though.
Regards,
Koji
-----Original Message-----
From: public-i18n-core-request@w3.org [mailto:public-i18n-core-request@w3.org] On Behalf Of Phillips, Addison
Sent: Friday, May 06, 2011 6:39 AM
To: public-i18n-core@w3.org
Subject: Normalization of CSS Selectors: a rough outline [I18N-ACTION-39]
In yesterday's I18N Core Teleconference [1], we discussed the question of normalization in CSS Selectors.
CSS has an excellent summary of much of the previous discussion here: [2].
This is a personal summary meant to help address ACTION-39 from our call. We'll discuss this next week (along with any replies, etc.) in an attempt to arrive at a recommendation to the CSS WG.
Basically the question is whether or not CSS Selectors [3] should use Unicode Normalization when selecting elements, attributes, and other text values. For example, if I write a selector:
.\C5land { color : green } // U+00C5 is Å
Which of the following does it select:
<p class="Åland">same form</p>
<p class="Åland">combining ring above; i.e. matched by NFC</p>
<p class="Åland">angstrom sign; a compatibility equivalent, i.e. matched by NFKC</p>
If we look at the solutions proposed, here's my analysis:
1. Require text input methods to produce normalized text
2. Require authoring applications to normalize text
This is the current state of affairs. Content authors are responsible for writing out files using a consistent normalization form. The statements appear to focus on making requirements to the input layer or authoring tools, however, a spec such as CSS cannot really directly specify these things. All CSS can really say is "pre-normalization of all input is assumed". The DOM, JavaScript, CSS, HTML, etc. do nothing to ensure a match. In the above example, the selector matches only the first item in the HTML fragment shown. Interoperability is thus dependent on everyone using the same normalization form at all times.
One additional pro not listed is: you can separately select each of the above cases (one additional con is that you must select them separately).
Since this working group gave up on Early Uniform Normalization (EUN), this has been basically the way that all Web technologies have worked. For the main "commercially interesting" languages of the world today, which are generally generated solely in form NFC, the interoperability problem is rare and typically requires special effort (translation: the above example is bogus). However, some scripts and languages *do* have this problem regularly.
3. Require consuming software to normalization input stream before parsing
This is Early Uniform Normalization. EUN is part of CharMod's recommendations. This WG well knows that we have failed at every attempt to get it enshrined into other W3C standards and thus we do not believe that this is a valid/available option to discuss.
4. Specify normalizing character encodings and have authors use them
This would be a special case of (3). I think the invention of additional "normalizing encodings" would be a Bad Thing.
5. Require all text in a consistent normalization on the level of document conformance
This means that EUN is not required, but non-normalized documents generate a complaint in the Validator/Tidy, etc. It's effectively equivalent to 1 & 2. A warning might be nice to have, but most documents never encounter a validator.
6. String matching-time late normalization
7. Interning-time normalization of identifiers
So having eliminated EUN, we come to the crux of the question: should Selectors use Unicode Normalization when performing matches against element and attribute values in the DOM (and potentially, in the future, against in-line content). This is called "Late Normalization". The WG appears to be tentatively in favor of using NFC when performing selection. This would help document authors create reliable selectors that find and match canonically equivalent strings--that is, strings that are visually and semantically identical--in their content.
I think (7) is problematic for the reasons described in the document. If identifiers are normalized at interning time, this would affect e.g. the DOM structure of the document and suggests that any process (JavaScript) that modifies the document's structure would also have to be somehow aware of normalization when querying the normalized values. Changing the structure of identifiers on-the-fly would probably lead to many complex bugs.
Specifying that string matching for selectors be normalized isn't described accurately in the CSS document [2]. For one thing, the normalization form really must be defined (it must at least decide between canonical and compatibility decomposition; whether it is a C or D form does not matter so long as consistent, but "none" is not permissible as a choice).
Personally, I see the real attraction to using normalization in string matching. Requiring NFC/NFD normalization on CSS Selectors would produce seamless selection for documents and document content across scripts, character encodings, transcodings, input methods, etc. consistent with user expectations.
However, I have to say that it would be, basically, the ONLY place in the full edifice of the modern Web where normalization is actively applied. It would require changes to at least JavaScript and CSS implementations and probably a number of other places. Existing implementations would have incompatible behavior.
Thus I would recommend that we continue on the current course:
1. Document that selectors are non-normalizing. Authors must be aware of content normalization concerns, especially for languages that are affected by normalization issues.
2. Recommend that documents, including stylesheets, be saved in Unicode Normalization Form C. Potentially include a warning in the validators.
Thoughts? Reactions? Different conclusions?
Addison
[1] http://www.w3.org/2011/05/04-i18n-minutes.html
[2] http://www.w3.org/wiki/I18N/CanonicalNormalization
[3] http://www.w3.org/TR/css3-selectors
Addison Phillips
Globalization Architect (Lab126)
Chair (W3C I18N WG)
Internationalization is not a feature.
It is an architecture.
Attachments
- image/png attachment: image001.png
- image/gif attachment: image002.gif

Received on Friday, 6 May 2011 05:25:30 UTC