- From: Robert Burns <rob@robburns.com>
- Date: Sun, 26 Aug 2007 21:49:33 -0500
- To: Boris Zbarsky <bzbarsky@MIT.EDU>
- Cc: public-html@w3.org
- Message-Id: <082B9BFA-E953-4440-B8AA-4B2DA4233880@robburns.com>
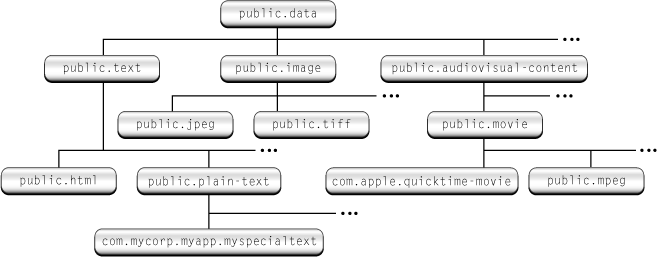
Hi Boris, Again, as a reminder I did create a wiki page on this issue[1]. Responses below. On Aug 24, 2007, at 3:50 PM, Boris Zbarsky wrote: > I agree that investigating this might be worthwhile. Some comments: > >> 1) what is the source of author error in setting file type >> information > > The main sources I've seen are ignorance and inability to affect > the server configuration, with the latter being very common. > > This combines with web servers that default unknown files to types > that majority UAs ignore and sniff (e.g. text/plain), to produce a > situation where there is little incentive for authors to either > learn or to seek out hosting providers that allow types to be set > on the server side. One solution here might be to make use of WebDAV extended attributes and have server's treat those with higher precedence than filename extensions or MIMEMagic. This would be a much more sensible approach since authors would be setting the MIME type of files directly rather than relying on wiring mapping files (however the implementation of those WebDAV extended attributes are handled on the back-end. > For example, nearly all OS X disk image files I've run into on the > web have been served as text/plain. And it seems that the people > serving them are OK with this. > > The ignorance aspect shows up in two common ways: allowing the web > server to send its default type for the data, and using a server- > side solution that sends out a default MIME type unless overridden > (e.g. PHP often defaults to text/html) for generating all their > documents. This way you get stylesheets, scripts, etc served as > text/html. Yeah, that doesn't sound good. I guess IE-sniffing made this all become common practice in the early days of PHP server apps. >> • For local files, filename extensions have become the nearly >> universal practice for setting file type handling in local file >> systems. > > Which is unfortunate, since extensions do not uniquely determine > type (the "rpm" and "xml" extensions are good examples). I assume by 'rpm' you're referring to it meaning RealPlayer media and Redhat Package Manager in different places. Part of the problem there is the obsession with thee-letter-extensions. Those could be replaced with .realplayer and .redhatpm and the problem would be fixed. I know that's not necessarily a good solution after the fact, but it would be a better practice for those inventing filename extensions in the first place. For .xml, I'm not sure what you're referring to. Do you mean that .xml can map either to text/xml or application/xml? The distinction in the MIME types is itself ambiguous so I don't see the problem with not clearly mapping to one or the other. My understanding is that there's an RFC that deprecates 'text/xml'[2]. Or are you referring to the fact that application/xml defines many flavors of XML. This to me is not that much of a problem. As I've said before in this thread, I think UAs should be capable of handling XML sub-types as XML as well. For example receiving an atom feed, a browser should be able to switch between either the feed presentation of a raw XML tree representation or even a raw source text representation (as many already do). > In practice, various operating systems and applications use data > other than the extension to decide what to do with the data > (content sniffing, generall, but OS X 10.4 and later has a way of > tagging files with type information independent of the filename or > raw data bytes). I assume here you're talking about Mac OS X's UTIs. However, UTIs do not tag files themselves. UTIs still rely on filename extensions (or the generally discouraged practice of using the type code and create code filesystem attributes). The system uses property list declarations within executable bundles to map the filename extensions, MIME types, creator codes, and type codes to the proper UTI. Tagging files with a UTI filesysten attribute might be the way to go in the future,, but I don't think a move like that would be good unless the whole industry wants to move away from filename extensions. However, UTIs do raise another aspect of this similar to the XML flavors issue. That is that UTIs define an elaborate hierarchy of types where each type inherits aspects from different lines of inheritance[3]. So for example an rtfd (com.apple.rtfd) inherits from both com.apple.package and public.composite- content. Those in turn inherit from other parent types on up the inheritance chain. So a document of type com.apple.rtrfd can be treated as any parent type by an application. This means applications that do not know how to treat an rtfd specifically can still be used to view or edit the rtfd file (in its own particular way). This is similar to the atom feed where the atom feed type would inherit from the public.xml UTI. This suggests to me that these conformance hierarchies basically represent all of the ways an HTML author might want to treat a particular sub-resource. There may be some other exceptions where authors want to treat a file as something outside this conformance hierarchy, but I would think it's pretty rare. A problem with using UTIs instead of MIME types is that MIME types reveal their hierarchies in their names. UTIs would require a method of dynamic discovery of UTI conformance hierarchies. So while UTIs provide an excellent mechanism for a decentralized UTI creation (using one's internet domain name in reverse order as a prefix for any UTI name), it still requires the environment to be configured and updated with proper UTI declarations. >> It would be useful to determine if authors make any significant >> number of errors in setting filename extensions. > > Insofar as extensions are usable for type identification given the > issues above, generally no. In my experience. Of course that > doesn't help dynamically-generated content. So are webapp authors not setting MIME types for their HTTP responses? I guess that sounds like an evangelism issue. >> a missing filename extension (needed once the file goes tot he >> server or is accessed using HTTP). > > For what it's worth, Apache does have a mode where it will use > content-sniffing instead of filename extensions to determine the > types it will send. It's not enabled by default (which is too > bad), and I don't know how commonly it's used. It seems to me that by changing the default user configuration file for Apache could have a more profound impact than creating a new RFC or W3C recommendation. Having it use the MIMEMagic would be an problem however since filename extensions would be the best mechanism for authors to deliberately change how a file was handled. So I think most administrators would still want the filename extension determination to have higher priority. But if the server doesn't recognize the filename extension, it may not recognize the file's content either. Someone would probably need to write a comprehensive MIMEMagic configuration file so that server admins could rely on it. For Apache to fix those bugs would be a better approach IMO. >> I suspect the server mapping issue is a big source of the problem. > > Absolutely. It's particularly a problem when a "new" extension > that the server is not aware of appears or becomes popular. > >> Typically the problem may occur when new file formats become >> common where the server has been installed and configured long >> before those formats (and their associated filename extensions) >> came onto the scene. > > As a UA developer, I can say that this is in fact the situation > that forced Gecko to add text/plain sniffing. > >> For example, if we explore these issues, and determine that >> filename extensions nearly universally reflect the authors >> intentions, then perhaps content sniffing is not the way to go > > Filename extensions don't cover dynamically generated content, for > which the relevant extensions are typically "php", "asp", "pl", > "exe", "cgi". If the dynamically generated content is a direct in-memory response from the server without creating a separate file, then the filename extensions would not be relveant would they? However, if dynamically generated content is first saving files to static file before sending the response, then this again looks like the problem of too short of a filename extension. These could be .phphtml and .phpcss.; or siimply .html and .css. Take care, Rob [1]: <http://esw.w3.org/topic/HTML/ContentTypeIssues> 2: <http://www.ietf.org/rfc/rfc3470.txt> 3
Attachments
- image/gif attachment: conformance_hierarchy.gif
Received on Monday, 27 August 2007 02:49:46 UTC