- From: Sean Hayes <Sean.Hayes@microsoft.com>
- Date: Thu, 22 Apr 2010 19:50:37 +0000
- To: Ian Hickson <ian@hixie.ch>, Dick Bulterman <Dick.Bulterman@cwi.nl>, "Eric Carlson" <eric.carlson@apple.com>, Frank Olivier <franko@microsoft.com>
- CC: HTML Accessibility Task Force <public-html-a11y@w3.org>
- Message-ID: <8DEFC0D8B72E054E97DC307774FE4B911A4F8454@DB3EX14MBXC303.europe.corp.microsoft.c>
Use case for inline styling.
This is indeed somewhat rare, however in Europe colour and in the US typography, is used to denote speaker. If as occasionally happens, multiple speakers are encoded in the same caption because they are speaking at the same time, then may be necessary to have multiple styles for one cued caption:
e.g.
Are you going?
Yes. No.
It is however possible if the layout system is sufficiently flexible, that these could be implemented as separate captions with overlapping display times. Sometimes the second utterance may need to appear marginally later than the first, and this may be implemented by animating a display style.
Scrolling (horizontally as in ticker tape, or vertically as in US rollup style captions), can also be implemented using animated styles.
There is a technical use for inline styling and timing as well, Captions that are auto-converted from CEA-608 format (which is probably the largest single source of caption data), may need to use this because captions in that format are delivered two characters per field (4 characters per frame), and may include real-time error correction (when the caption source was from a stenographer) altering characters inline. It is sometimes easier to replicate exactly what the 608 source does, rather than try to figure out what the 'right' caption was.
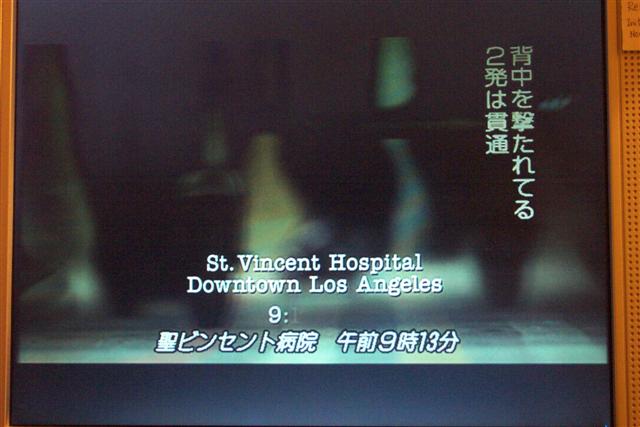
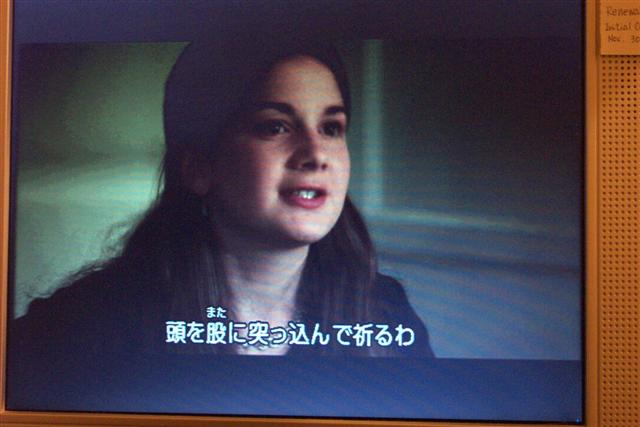
Another use case to consider is vertical text, as is sometimes used in Japanese subtitling (see attachment DCP0361), and mixing this with horizontal text. In DCP 0367 there is an example of furigana (Ruby) text.
Use case of relative timing:
The advantage of relative timing is mainly seen at the editing stage, it is easier to simply change the duration of one caption, and have all the subsequent ones move up automatically, than it is to change the onset time of every caption. However since most authoring will be tool supported, (as captioning anything other than a minute or two of video by hand is extremely tedious and error prone), this may not be an absolute requirement for playback. Should <video> start to support fragment indexing or playlists however, then this could become more useful.
-----Original Message-----
From: Ian Hickson [mailto:ian@hixie.ch]
Sent: Thursday, April 22, 2010 8:03 PM
To: Dick Bulterman; Eric Carlson; Sean Hayes; Frank Olivier
Cc: HTML Accessibility Task Force
Subject: Re: [media] WHATWG started requirements collection for time-aligned text
On Thu, 22 Apr 2010, Dick Bulterman wrote:
>
> On the timed text tracks, I would (once again) like to suggest that
> rather than inventing yet another form of timed text, the WHATWG look
> at the work on smilText.
I'm looking at many existing formats; TTML, smilText, SRT, LRC, SSA, USF, etc etc etc. For each one, I'm looking at simplicity, ease of authoring, how well it addresses the use cases described here:
http://wiki.whatwg.org/wiki/Use_cases_for_timed_tracks_rendered_over_video_by_the_UA
http://wiki.whatwg.org/wiki/Use_cases_for_API-level_access_to_timed_tracks
...(if you have other use cases from real world videos I should consider, let me know!), how well it avoids feature creep (i.e. how few things it supports that _aren't_ in the use cases above), how well the community has adopted it, what kind of response it got from the various Web communities that do captioning, and so on.
> This format can be dropped into HTML-5 with little or no change and
> provides the following advantages:
> 1. It supports absoulte and relative timing of text fragments,
Can you elaborate on this? I haven't come across a use case for that yet.
What is the need for this feature?
> 2. It allows CSS to be used for styling text objects
Is there a use case for intra-cue (inline) styling of cues? I haven't found any examples that do styling at anything more than the per-cue level, and even that is rare (most do it at the global per-track level or even the per-user-agent level, e.g. TVs just have a single user-set style that applies to all captions).
> 3. It is intuitive for hand-authors, but can also be generated
All these formats can be generated. I would say smilText scores amongst the worst in terms of hand authoring. Compare it to, for instance, SRT.
> 4. It is structured into a basic module, a styling module and a text
> motion module, so that growth is possbile
Modularity isn't necessary for extensions.
> 5. It can be supported in an external file as a streaming format or in-line.
Are there formats where that is not the case?
> The disadvantages?
> 1. It was not invented by this group.
That's an advantage, actually, not a disadvantage. The less we have to invent the better. If we can't reuse an existing format directly, then at most I hope we can reuse an existing format in a backwards-compatible way, so that existing deployed tracks can be reused. Leverging network effects is a big way to ensure adoption -- we don't have a magic wand that causes people to automatically do whatever we say! If anyone has examples of "real world" usage of various subtitle formats, that would be great.
On Thu, 22 Apr 2010, Sean Hayes wrote:
>
> It seems to me that we are once again heading towards the impasse that
> happened when trying to bless a single video and audio codec. It seems
> likely to me that the solution should focus on how the association is
> made, where it shows up, and if necessary (which I don't think it is)
> any API or event model associated, and not get bogged down in which
> format has the most friends.
I hope that we can avoid that impasse in this case. I am already working closely with vendors to get their take on what they will or won't implement.
I agree with you that whatever we do it should have a format-agnostic part. The proposals listed in the bugs:
http://www.w3.org/Bugs/Public/show_bug.cgi?id=9452
http://www.w3.org/Bugs/Public/show_bug.cgi?id=9471
...are format agnostic. The general approach used by those proposals seems sound, and I expect to use that approach.
On Thu, 22 Apr 2010, Frank Olivier wrote:
>
> I agree with Sean; converting between captioning formats is a trivial
> problem; the harder (and more pressing) problem is getting some form
> into support into widespread usage by all browsers.
Indeed.
--
Ian Hickson U+1047E )\._.,--....,'``. fL
http://ln.hixie.ch/ U+263A /, _.. \ _\ ;`._ ,.
Things that are impossible just take longer. `._.-(,_..'--(,_..'`-.;.'
Attachments
- image/jpeg attachment: DCP_0361__Small_.JPG
- image/jpeg attachment: DCP_0367__Small_.JPG
Received on Thursday, 22 April 2010 19:51:02 UTC